

Nâng cao hiệu năng tính toán cho các bài toán tìm đường đi ngắn nhất và cây khung nhỏ nhất
1. Lý do chọn đề tài
Công nghệ thông tin đang phát triển với một tốc độ chóng mặt, di cùng đó là lượng dữ liệu khổng lồ. Để xử lý lượng dữ liệu khổng lồ đó đòi hỏi khối lượng tính toán rất lớn và thời gian là yếu tố quyết định tính thực tiễn của bài toán đó.Để tăng tốc độ tính toán, các nhà khoa học đã đưa ra hai giải pháp:
Thứ nhất là cải tiến công nghệ, tăng tốc độ xử lý của máy tính. Công việc này đỏi hỏi nhiều thời gian, công sức và tiền bạc nhưng tốc độ thì chỉ đạt đến một giới hạn nhất định.
Thứ hai là chia bài toán ra thành những bài toán nhỏ để chạy song song trên nhiều bộ xử lý.
Các nhà khoa học đã tập trung nghiên cứu ở giải pháp thứ hai, từ đó ra đời thuật toán song song. Đó là việc sử dụng đồng thời nhiều tài nguyên tính toán để giải quyết một bài toán. Các tài nguyên tính toán có thể bao gồm một máy tính với nhiều bộ vi xử lý hay một tập các máy tính kết nối mạng hay là một sự kết hợp của hai dạng trên. Công nghệ tính toán song song cho phép giảm thời gian thực thi bài toán tùy thuộc cách phân chia và số bộ xử lý thực thi chương trình. Nguyên tắc quan trọng nhất của tính toán song song chính là tính đồng thời hay xử lý nhiều tác vụ cùng một lúc.
Với mục đích tìm hiểu và nghiên cứu về thuật toán song song để giải quyết bài toán đồ thị một cách hiệu quả hơn, thời gian xử lý ngắn hơn do đó tôi chọn đề tài: “Nâng cao hiệu năng tính toán cho các bài toán tìm đường đi ngắn nhất và cây khung nhỏ nhất “
2. Mục tiêu và nhiệm vụ
2.1. Mục tiêu
Nghiên cứu thuật toán song song, ứng dụng một thư viện cụ thể nâng cao hiệu năng tính toán cho hai thuật toán Dijkstra và Prim nhằm giảm thời gian thực hiện, góp phần nâng cao hiệu năng hoạt động của hệ thống.
2.2. Nhiệm vụ
- Tìm hiểu về lý thuyết đồ thị.
- Nghiên cứu về xử lý song song và lập trình song song.
- Xây dựng và giải quyết một số bài toán đồ thị dự theo mô hình thư viện MPI.
- Cài đặt và đánh giá kết quả bài toán.
3. Đối tượng và phạm vi nghiên cứu:
3.1. Đối tượng nghiên cứu của đề tài
- XLSS và thuật toán song song.
- Các bài toán đồ thị.
- Lập trình song song với MPI.
3.2. Phạm vi nghiên cứu của đề tài
- Tổng quan về XLSS và phân tán.
- Tổng quan về lý thuyết đồ thị.
4. Phương pháp nghiên cứu
4.1. Nghiên cứu lý thuyết
- XLSS và thuật toán song song.
- Đồ thị và các bài toán trên đồ thị.
- Tìm hiểu lập trình song song với MPI.
4.2. Nghiên cứu thực nghiệm
- Xây dựng sơ đồ, thuật toán song song.
- Lập trình song song với MPI bằng Visual Studio.
5. Bố cục đề tài
Ngoài phần mở đầu và kết thúc, nội dung chính của luận văn có 4 chương.
Chương 1: Xử lý song song.
Chương 2: Lập trình song song.
Chương 3: Các thuật toán trên đồ thị.
Chương 4: Nghiên cứu ứng dụng thuật toán song song trên thư viện MPI.
6. Ý nghĩa khoa học và thực tiễn của đề tài
Nghiên cứu và nâng cao hiệu năng của hệ thống bằng XLSS.
Có thể áp dụng cho một số lĩnh vực cụ thể và một số bài toán có độ phức tạp về thời gian lớn, những bào toán thời gian thực.

XỬ LÝ SONG SONG
Giới thiệu về xử lý song song
Ngày nay, rất nhiều bài toán yêu cầu khả năng tính toán và lưu trữ rất lớn thì mô hình kiến trúc này còn hạn chế. Do đó để giải quyết các bài toán này cần có những hệ thống máy tính đủ mạnh để thực hiện một cách nhanh chóng và hiệu quả. Vì vậy, hướng xử lý song song với việc kết hợp nhiều bộ xử lý vào trong một máy tính được lựa chọn để giải quyết các bài toán đặt ra.
Xử lý song song hay tính toán song song là quá trình xử lý gồm nhiều tiến trình được kích hoạt đồng thời và cùng tham gia giải quyết một vấn đề, nói chung là thực hiện tính toán trên những hệ thống đa bộ xử lý [1].
Máy tính song song là tập hợp các bộ xử lý kết nối với nhau theo một kiến trúc xác định cùng hợp tác hoạt động và trao đổi song song.
Kiến trúc máy tính song song
Mô hình SISD
Kiến trúc song song SIMD
Kiến trúc song song MISD
Mô hình máy tính MIMD
Các mô hình lập trình song song
Mô hình chia sẽ bộ nhớ
Mô hình luồng
Mô hình truyền thông điệp
Mô hình phân hoạch dữ liệu
Thuật toán song song
Quy trình thiết kế thuật toán song song
Nguyên lý thiết kế thuật toán song song
Các cách tiếp cận trong thiết kế
Phân tích đánh giá thuật toán song song
Trong thuật toán tuần tự chúng ta chỉ quan tâm đến độ phức tạp về thời gian và không gian, nhưng trong thuật toán song song thường có thêm một số đại lượng đo lường khác. Độ phức tạp thời gian của thuật toán song song không chỉ đơn giản là việc đếm số câu lệnh cơ bản như trong thuật toán tuần tự mà thay vào đó nó phụ thuộc vào các phép toán cơ bản này có thể được thực hiện trên p bộ xử lý như thế nào. Bên cạnh độ phức tạp thời gian độ phức tạp về số bộ xử lý cũng là một đại lượng quan trọng trong phân tích thiết kế thuật toán song song.
Thiết kế thuật toán song song hiệu quả bao gồm việc lựa chọn cấu trúc dữ liệu phù hợp, phân bố bộ xử lý và cuối cùng là thực hiện thuật toán. Ba đại lượng này tác động lẫn nhau như một tổ chức tính toán.
Kết luận chương
LẬP TRÌNH SONG SONG VỚI MPI
Tổng quan về lập trình song song trong môi trường MPI
Giới thiệu
Một số đặc điểm của lập trình MPI
Lập trình song song với môi trường MPI
Giới thiệu
Giao thức truyền thông điệp MPI là một thư viện các hàm và macro có thể được gọi từ các chương trình sử dụng ngôn ngữ C, Fortran, và C++. Như tên gọi của nó MPI được xây dựng nhằm sử dụng trong các chương trình để khai thác hệ thống các bộ xử lý bằng cách truyền thông điệp.
Một số vấn đề hiệu năng
Năng lực tính toán
Cân bằng tải
Sự bế tắc
Tìm hiểu tập lệnh của thư viện MPI
Các lệnh quản lý môi trường MPI
Các lệnh này có nhiệm vụ thiết lập môi trường cho các lệnh thực thi MPI, truy vấn chỉ số của tác vụ, các thư viện MPI, …
– MPI Init khởi động môi trường MPI
MPI_Init (&argc, &argv)
Init ((argc, argv)
– MPI Comm size trả về tổng số tác vụ MPI đang được thực hiện trong communicator (chẳng hạn như trong MPI_COMM_WORLD)
MPI_Comm_size (comm,&size)
Comm::Get_size()
– MPI Comm rank trả về chỉ số của tác vụ (rank). Ban đầu mỗi tác vụ sẽ được gán cho một số nguyên từ 0 đến (N-1) với N là tổng số tác vụ trong communicator
MPI_COMM_WORLD.
MPI_Comm_rank (comm, &rank)
Comm::Get_rank()
– MPI Abort kết thúc tất cả các tiến trình MPI
MPI_Abort (comm, errorcode)
Comm::Abort(errorcode)
– MPI Get processor name trả về tên của bộ xử lý
MPI_Get_processor_name(&name, &resultl)
Get_processor_name(&name, resultlen)
– MPI Initialized trả về giá trị 1 nếu MPI_Init() đã được gọi, 0 trong trường hợp ngược lại
MPI_Initialized (&flag)
Initialized (&flag)
– MPI Wtime trả về thời gian chạy (tính theo giây) của bộ xử lý
MPI_Wtime ()
Wtime ()
– MPI Wtick trả về độ phân giải thời gian (tính theo giây) của MPI_Wtime()
MPI_Wtick ()
Wtick ()
– MPI _ Finalize kết thúc môi trường MPI
MPI_Finalize ()
Finalize ()
Các kiểu dữ liệu
Cơ chế truyền thông điệp
Các lệnh truyền thông điệp blocking
Một số lệnh thông dụng cho chế độ truyền thông điệp blocking gồm có:
– MPI Send gửi các thông tin cơ bản
MPI_Send(&buf,count,datatype,dest,tag,comm) Comm::Send(&buf,count,datatype,dest,tag)
– MPI Recv nhận các thông tin cơ bản
MPI_Recv(&buf,count,datatype,source,tag,comm,&status) Comm::Recv(&buf,count,datatype,source,tag,status)
– MPI Ssend gửi đồng bộ thông tin, lệnh này sẽ chờ cho đến khi thông tin đã được nhận (thông tin được gửi sẽ bị giữ lại cho đến khi bộ đệm của tác vụ gửi được giải phóng để có thể sử dụng lại và tác vụ đích (destination process) bắt đầu nhận thông tin)
MPI_Ssend (&buf,count,datatype,dest,tag,comm)
Comm::Ssend(&buf,count,datatype,dest,tag)
– MPI Bsend tạo một bộ nhớ đệm (buffer) mà dữ liệu được lưu vào cho đến khi được gửi đi, lệnh này sẽ kết thúc khi hoàn tất việc lưu dữ liệu vào bộ nhớ đệm.
MPI_Bsend (&buf,count,datatype,dest,tag,comm)
Comm::Bsend(&buf,count,datatype,dest,tag)
– MPI Buffer attach cấp phát dung lượng bộ nhớ đệm cho thông tin được sử dụng bởi lệnh MPI_Bsend()
MPI_Buffer_attach (&buffer,size)
Attach_buffer(&buffer,size)
– MPI Buffer detach bỏ cấp phát dung lượng bộ nhớ đệm cho thông tin được sử dụng bởi lệnh MPI_Bsend()
MPI_Buffer_detach (&buffer,size)
Detach_buffer(&buffer,size)
– MPI Rsend gửi thông tin theo chế độ ready, chỉ nên sử dụng khi người lập trình chắc chắn rằng quá trình nhận thông tin đã sẵn sàng.
MPI_Rsend (&buf,count,datatype,dest,tag,comm)
Comm::Rsend(&buf,count,datatype,dest,tag)
– MPI Sendrecv gửi thông tin đi và sẵn sàng cho việc nhận thông tin từ tác vụ khác
MPI_Sendrecv (&sendbuf,sendcount,sendtype,dest,sendtag,
&recvbuf,recvcount,recvtype,source,recvtag,comm,&status)
Comm::Sendrecv(&sendbuf,sendcount,sendtype,dest,sendtag,
&recvbuf,recvcount,recvtype,source,recvtag,status)
– MPI Wait chờ cho đến khi các tác vụ gửi và nhận thông tin đã hoàn thành
MPI_Wait (&request,&status)
Request::Wait(status)
– MPI Probe kiểm tra tính blocking của thông tin
MPI_Probe(source,tag,comm,&status)Comm::Probe(source,tag,status)
Các lệnh truyền thông điệp non-blocking
Một số lệnh thông dụng cho chế độ truyền thông điệp non-blocking gồm có:
MPI Isend gửi thông điệp non-blocking, xác định một khu vực của bộ nhớ thực hiện nhiệm vụ như là một bộ đệm gửi thông tin.
MPI_Isend (&buf,count,datatype,dest,tag,comm,&request)
Request Comm::Isend(&buf,count,datatype,dest,tag)
– MPI Irecv nhận thông điệp non-blocking, xác định một khu vực của bộ nhớ thực hiện nhiệm vụ như là một bộ đệm nhận thông tin.
MPI_Irecv (&buf,count,datatype,source,tag,comm,&request)
Request Comm::Irecv(&buf,count,datatype,source,tag)
– MPI Issend gửi thông điệp non-blocking đồng bộ (synchronous).
MPI_Issend (&buf,count,datatype,dest,tag,comm,&request)
Request Comm::Issend(&buf,count,datatype,dest,tag)
– MPI Ibsend gửi thông điệp non-blocking theo cơ chế buffer.
MPI_Ibsend (&buf,count,datatype,dest,tag,comm,&request)
Request Comm::Ibsend(&buf,count,datatype,dest,tag)
– MPI Irsend gửi thông điệp non-blocking theo cơ chế ready.
MPI_Irsend (&buf,count,datatype,dest,tag,comm,&request)
Request Comm::Irsend(&buf,count,datatype,dest,tag)
– MPI Test kiểm tra trạng thái kết thúc của các lệnh gửi và nhận thông điệp non-blocking Isend(), Irecv(). Tham số request là tên biến yêu cầu đã được dùng trong các lệnh gửi và nhận thông điệp, tham số flag sẽ trả về giá trị 1 nếu thao tác hoàn thành và giá trị 0 trong trường hợp ngược lại.
MPI_Test (&request,&flag,&status)
Request::Test(status)
– MPI Iprobe kiểm tra tính non-blocking của thông điệp
MPI_Iprobe(source,tag,comm,&flag,&status) Comm::Iprobe(source,tag,status)
Các lệnh truyền thông tập thể
Một số lệnh thông dụng cho cơ chế truyền thông tập thể gồm có:
– MPI Barrier lệnh đồng bộ hóa (rào chắn), tác vụ tại rào chắn (barrier) phải chờ cho đến khi tất cả các tác vụ khác trên cùng một communicator đều hoàn thành.
MPI_Barrier (comm)
Intracomm::Barrier()
– MPI Bcast gửi bản sao của bộ đệm có kích thước count từ tác vụ root đến tất cả các tiến trình khác trong cùng một communicator.
MPI_Bcast (&buffer,count,datatype,root,comm) Intracomm::Bcast(&buffer,count,datatype,root)
– MPI Scatter phân phát giá trị bộ đệm lên tất cả các tác vụ khác, bộ đệm được chia thành sendcnt phần.
MPI_Scatter(&sendbuf,sendcnt,sendtype,&recvbuf,recvcnt,recvtype,root,comm)
Intracomm::Scatter(&sendbuf,sendcnt,sendtype,&recvbuf,recvcnt,recvtype,root)
– MPI Gather tạo mới một giá trị bộ đệm riêng cho mình từ các mảnh dữ liệu gộp lại.
MPI_Gather(&sendbuf,sendcnt,sendtype,&recvbuf,recvcnt,recvtype,root,comm)
Intracomm::Gather(&sendbuf,sendcnt,sendtype,&recvbuf,recvcnt,recvtype,root)
– MPI Allgather tương tự như MPI_GATHER nhưng sao chép bộ đệm mới cho tất cả các tác vụ.
MPI_Allgather(&sendbuf,sendcnt,sendtype,&recvbuf,recvcount,recvtype,comm)
Intracomm::Allgather(&sendbuf,sendcnt,sendtype,&recvbuf,recvcnt,recvtype)
– MPI _ Reduce áp dụng các toán tử rút gọn (tham số op) cho tất cả các tác vụ và lưu kết quả vào một tác vụ duy nhất.
MPI_Reduce
(&sendbuf,&recvbuf,count,datatype,op,root,comm)
Intracomm::Reduce(
&sendbuf,&recvbuf,count,datatype,op,root)
– Các toán tử rút gọn gồm có: MPI_MAX (cực đại), MPI_MIN (cực tiểu), MPI_SUM (tổng), MPI_PROD (tích), MPI_LAND (toán tử AND logic), MPI_BAND (toán tử AND bitwise), MPI_LOR (toán tử OR logic), MPI_BOR (toán tử OR bitwise), MPI_LXOR (toán tử XOR logic), MPI_BXOR (toán tử XOR bitwise), MPI_MAXLOC (giá tri cực đại và vi trí), MPI_MINLOC (giá tri cực tiểu và vi trí).
– MPI Allreduce tương tự như MPI_Reduce nhưng lưu kết quả vào tất cả các tác vụ.
MPI_Allreduce(&sendbuf,&recvbuf,count, datatype,op,comm)
Intracomm::Allreduce(&sendbuf,&recvbuf,count, datatype,op)
– MPI Reduce scatter tương đương với việc áp dụng lệnh MPI_Reduce rồi tới lệnh MPI_Scatter.
MPI_Reduce_scatter(&sendbuf,&recvbuf,recvcount,datatype,op,comm) Intracomm::Reduce_scatter(&sendbuf,&recvbuf,recvcount[], datatype,op)
– MPI Alltoall tương đương với việc áp dụng lệnh MPI_Scatter rồi tới lệnh MPI_Gather.
MPI_Alltoall(&sendbuf,sendcount,sendtype,&recvbuf,recvcnt,recvtype,comm)
Intracomm::Alltoall(&sendbuf,sendcount,sendtype,&recvbuf,recvcnt,recvtype)
– MPI Scan kiểm tra việc thực hiện toán tử rút gọn của các tác vụ.
MPI_Scan(&sendbuf,&recvbuf,count,datatype,op,comm) Intracomm::Scan(&sendbuf,&recvbuf,count, datatype,op)
CÁC THUẬT TOÁN TRÊN ĐỒ THỊ
Thuật toán Dijkstra tìm đường đi ngắn nhất
Mô tả thuật toán
+ Đầu vào: Đồ thị liên thông G(V,E,w), w(i,j) > 0 (i,j) E, đỉnh nguồn a.
+ Đầu ra : Chiều dài đường đi ngắn nhất và đường đi ngắn nhất từ đỉnh a đến các đỉnh của đồ thị.
+ Phương pháp :
Bước 1: Gán L(a):= 0. Với mọi đỉnh x a gán L(x) = . Đặt T:=V.
Bước 2: Chọn v T, v chưa xét sao cho L(v) có giá trị nhỏ nhất. Đặt T := T – {v}, đánh dấu đỉnh v đã xét.
Bước 3: Nếu T= , kết thúc. L(z), z V, z a là chiều dài đường đi ngắn nhất từ a đến z. Từ z lần ngược theo đỉnh được ghi nhớ ta có đường đi ngắn nhất. (L(z) không thay đổi, nếu L(z) = thì không tồn tại đường đi.
Ngược lại sang bước 4.
Bước 4: Với mỗi x T kề v gán L(x) := min {L(x), L(v) + w(v,x)}. Nếu L(x) thay đổi thì ghi nhớ đỉnh v cạnh đỉnh x bằng mảng truoc[] (với truoc[] của đỉnh 1 = 0) để sau này xây dựng đường đi ngắn nhất.
Quay về bước 2.
Độ phức tạp của thuật toán Dijkstra: Thuật toán dùng không quá n-1 bước lặp. Trong mỗi bước lặp, dùng không hơn 2(n-1) phép cộng và phép so sánh để sửa đỗi nhãn của các đỉnh. Ngoài ra, một đỉnh thuộc Sk có nhãn nhỏ nhất nhờ không quá n – 1 phép so sánh. Do đó thuật toán có độ phức tạp O(n2).
Ví dụ minh họa
Thuật toán tuần tự Prim tìm cây khung cực tiểu
Mô tả thuật toán
Đầu vào: Đồ thị G=(V,E) với trọng số. Các đỉnh ký hiệu là 1,2,3,…,n
Trọng số của cạnh (i,j), (i,j), ký hiệu là cij
Đầu ra: Cây phủ nhỏ nhất T, Hoặc kết luận đồ thị không liên thông.
Các bước:
(1) Khởi tạo: T là đồ thị gồm một đỉnh 1 và không có cạnh
(2) Kiểm tra điều kiện kết thúc:
Nếu T có n-1 cạnh, kết thúc, kết luận: T là cây phủ nhỏ nhất. Ngược lại sang bước (3)
(3) Thêm cạnh:
Ký hiệu M là tập M ={ (i,j)| i&j}
Tìm cạnh (k,h) sao cho :
ckh=min{cij|(i,j)}
Nếu ckh<∞, thêm cạnh (k,h) và đỉnh h vào T, sang bước (2). Ngược lại tức M=, kết thúc. Kết luận đồ thị G không liên thông
Ví dụ minh họa
NGHIÊN CỨU ỨNG DỤNG THUẬT TOÁN SONG SONG TRÊN THƯ VIỆN MPI
Thuật toán song song Prim tìm cây khung cực tiểu:
Cách thực hiện thuật toán:
Đầu vào: Đồ thị G=(V,E) với trọng số. Các đỉnh ký hiệu là 1,2,3,…,n
Trọng số của cạnh (i,j), (i,j), ký hiệu là cij
Đầu ra: Cây phủ nhỏ nhất T, hoặc kết luận đồ thị không liên thông
Các bước thực hiện:
Bước 1: Chia số đỉnh n và ma trận trọng số tương ứng của đồ thị cho m BXL (mỗi BXL nhận n/m đỉnh). BXL 1 đặt tên P1 có tập cạnh là E1, BXL 2 là P2 có tập cạnh là E2, …, BXL m là Pm có tập cạnh là Em
Bước 2: Bộ xử lý P1 gửi một đỉnh ban đầu lên cho các BXL P1,P2,…,Pm
Bước 3: Trên mỗi BXL (P1,P2,…,Pm) thực hiện các bước sau đây:
Khởi tạo T= (1 đỉnh mà P1 đã phát ra ở bước 2, không cạnh)
Bước 4: Kiểm tra điều kiện kết thúc:Nếu T có n-1 cạnh thì kết thúc, ngược lại sang bước 5
Bước 5: Thêm cạnh: Trên mỗi BXL Ký hiệu Mk là tập trên BXL k
Mk={(i,j) k i&j(k=1,…,m)}
Trên mỗi BXL tìm cạnh (xk,yk) (k=1,…,m)
sao cho =min{cij|(i,j) (k=1,…,m)}
Nếu tất cả các Mk trên tất cả m BXL là rổng thì kết thúc, kết luận đồ thị không liên thông, ngược lại sang bước 6
Bước 6: BXL P1 thực hiện tìm nhỏ nhất trên tất cả m BXL .
BXL P1 thêm cạnh (x,y) và đỉnh y vào T
BXL P1 chuyển số cạnh của T và đỉnh y lên tất cả các BXL để lặp lại bước 4
Ví dụ thực hiện thuật toán song song Prim
Thuật toán song song Dijkstra tìm đường đi ngắn nhất từ một đỉnh đến tất cả các đỉnh
Cách thực hiện thuật toán
Đầu vào: Đồ thị liên thông G(V,E,w), w(i,j) ≥ 0 (i,j)E, đỉnh nguồn a, 1 bộ xử lý chính và m-1 bộ xử lý phụ.
Đầu ra: Chiều dài đường đi ngắn nhất là đường đi ngắn nhất từ đỉnh a đến tất cả các đỉnh trên đồ thị.
Ý tưởng: Chia đồ thị ban đầu cho m bộ xử lý (P0, P1,…,Pm-1), cùng tính toán đồng thời, mỗi bộ BXL đảm nhận n/m đỉnh của đồ thị (n là số đỉnh của đồ thị, m là số BXL ) và ma trận trọng số n/m cột và n dòng
+Phương pháp:
Bước 1. Bộ xử lý chính thực hiện
– Gán L(a):=0. Với mọi đỉnh x ≠ a, x thuộc bộ xử lý chính gán L(x)= ∞.
– Chia đều số đỉnh và ma trận trọng số để gửi cho m BXL.
Cách chia đều như sau: giả sử ta có n đỉnh và m bộ xử lý P0,P1,…,Pm-1.
Gọi ni là số đỉnh của bộ xử lý Pi (i=0,…,m-1).
– Nếu n chia hết cho m thì
For i=0 to m-1 do
– Nếu n không chia hết cho m thì
For i=0 to m-2 do
– Ta xây dựng Ti (i=0,…,m-1) là tập đỉnh mà bộ xử lý Pi sẽ nhận như sau:
BN=0; kt là số phần tử mà các bộ xử lý nhận
for (k=0; k<m; k++)
{
Tk=;
for (j=0; j<kt; j++)
Tk=Tk+{j+ BN+1} }
– Ta xây dựng Ai (i=0,…,m-1) là ma trận trọng số mà bộ xử lý Pi sẽ nhận như sau:
Gọi A là ma trận trọng số của đồ thị đầu vào thì A=(wij)nxn.
HÌNH 4.1 Ma trận trọng số của đồ thị
Suy ra:sẽ được bộ xử lý Pi (i=0,…,m-1) nhận.
– Gửi Ti (i=1,..,m-1), Ai (i=1,..,m-1), L(x), xTi (i=1,..,m-1), cho m-1 BXL phụ P1,P2,…,Pm-1.
Bước 2. m bộ xử lý thực hiện
Trong m bộ xử lý (trừ bộ xử lý chính), gán L(xi)= ∞, sao cho xi thuộc
Ti (i=1,…,m-1).
Trên m bộ xử lý tìm Li(xi)= min{L(xi), xiTi (i=0,…,m-1), xi chưa xét}.
Các bộ xử lý phụ gửi Li(xi) về bộ xử lý chính.
Bước 3. Bộ xử lý chính thực hiện
Bộ xử lý chính tìm l(v)= min{Li(xi), i=0,..,m-1}trên m bộ xử lý.
– Chuyển đỉnh v lên m bộ xử lý để thực hiện các bước tiếp theo.
Bước 4. m bộ xử lý thực hiện
– Trên m BXL kiểm tra nếu v, Ti=Ti\{v} (i=0,…,m-1), đánh đấu đỉnh v đã xét.
– Kiểm tra nếu Ti (i=0,..,m-1) = , thì bộ xử lý thứ i kết thúc, sang bước 6.
– Ngược lại, sang bước 5.
Bước 5. m bộ xử lý thực hiện
for x Ti (i=0,…,m-1) kề với v
if L(x)>L(v)+w(v,x)
{ L(x) := L[v] + w(v,x)
Truoc[x]=v // ghi nhớ đỉnh v vào x }
quay lại bước 2.
Bước 6. Bộ xử lý chính thực hiện
Nếu tất cả m-1 bộ xử lý phụ kết thúc thì bộ xử lý chính thực hiện: nhận kết quả từ các bộ xử lý phụ và kết luận chiều dài đường đi ngắn nhất từ a đến tất cả các đỉnh và đường đi ngắn nhất qua các đỉnh đã ghi nhớ. Đỉnh nào có nhãn không thay đổi (bằng ∞) thì không tồn tại đường đi_(Not Path). Hệ thống kết thúc.
Ví dụ thực hiện thuật toán song song Dijkstra
Thực nghiệm chương trình
Chương trình được thực nghiệm trên hệ thống cụm máy tính song song (Parallel computer cluster) của trường Đại Học Sư phạm Hà Nội với hệ thống toàn cầu ccsl.hnue.edu.vn
Hệ thống máy tính của Trung tâm thường dùng để chạy các chương trình lớn, yêu cầu nhiều bộ xử lý và bộ nhớ. Sau khi truy cập hệ thống, người sử dụng có thể viết (hoặc gửi chương trình từ máy tính cá nhân của mình lên), biên dịch và chạy chương trình trên hệ thống của Trung tâm. Có 2 loại chương trình: single-node program (chương trình đơn, chạy trên 1 bộ xử lý) và multi-node program (chương trình song song); và có 2 cách thực hiện chương trình trên hệ thống PC cluster của CCS: chạy trực tiếp trên nền hệ điều hành và chạy thông qua Bộ quản lý chương trình Torque.
Đăng nhập hệ thống
Cách chạy chương trình trên hệ thống ccs1
Kết quả thu được
Dưới đây là kết quả bài toán Dijkstra với 02 BXL P0 và P1 với thời gian chạy là 0.002539 sescond
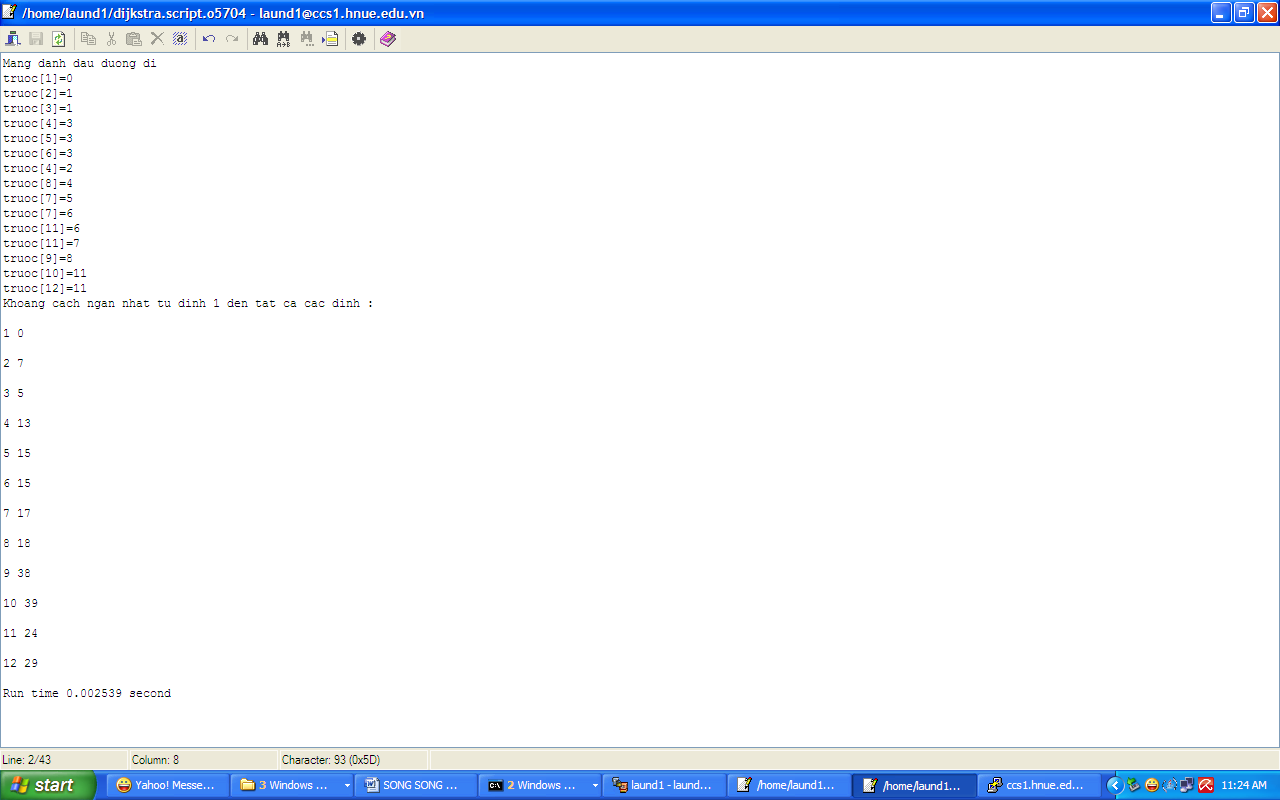
Bộ xử lý chính (P0) ghi nhớ các đỉnh để tìm đường đi
Bộ xử lý phụ (P1) ghi nhớ các đỉnh để tìm đường đi
Bộ xử lý chính (P0) tìm chiều dài từ đỉnh 1 đến các đỉnh 1, 2, 3, 4, 5, 6
Bộ xử lý phụ (P1) tìm chiều dài từ đỉnh 1 đến các đỉnh 7, 8, 9, 10, 11, 12
HÌNH 4.2. Kết quả thu được chạy bài toán Dijkstra trên hệ thống
Đánh giá thuật toán
Trong thuật toán song song người ta sử dụng tốc độ (Speedup)
Để đánh giá thời gian thực hiện của thuật toán song song so với thuật toán tuần tự.
Bài toán Dijkstra
Chúng tôi tiếp tục tạo thêm đồ thị gồm 2500 đỉnh và cho thực hiện trên 1 bộ xử lý (tuần tự), 2, 4, 6, 8 bộ xử lý thì kết quả được cho ở bảng sau:
BẢNG 4.1. Bảng đánh giá thời gian thực hiện thuật toán song song so với thuật toán tuần tự bài toán Dijkstra 2500 đỉnh
| Số bộ xử lý | 1 | 2 | 4 | 6 | 8 |
| Tốc độ (Speedup) | 200 | 275 | 290 | 302 | 314 |
Trong đó Speedup (tốc độ)= Ts/ Tp
Ts: Sequential time (Thời gian chạy tuần tự)
Tp: Parallel time (Thời gian chạy song song)
Bảng đánh giá trên được biểu diễn bằng đồ thị sau:
HÌNH 4.3. Đồ thị biểu diễn sự đánh giá thuật toán song song so với tuần tự bài toán Dijkstra 2500 đỉnh
Bài toán Prim
Chúng tôi tiếp tục tạo thêm đồ thị gồm 2100 đỉnh và cho thực hiện trên 1 bộ xử lý (tuần tự), 2, 4, 6, 8 bộ xử lý thì kết quả được cho ở bảng sau:
BẢNG 4.2. Bảng đánh thời gian thực hiện thuật toán song song so với thuật toán tuần tự bài toán Prim 2100 đỉnh
| Số bộ xử lý | 1 | 2 | 4 | 6 | 8 |
| Tốc độ (Speedup) | 205 | 266 | 287 | 308 | 320 |
Bảng đánh giá trên được biểu diễn bằng đồ thị sau:
HÌNH 4.4. Đồ thị biểu diễn sự đánh giá thuật toán song song so với tuần tự bài toán Prim 2100 đỉnh
Nhận xét: từ đồ thị và bảng kết quả trên, chúng ta nhận thấy rằng tốc độ xử lý được tăng lên đáng kể khi xử lý trên 2 bộ xử lý thì thời gian giảm hơn 1,6 lần so với xử lý tuần tự.
KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN
KẾT LUẬN
Luận văn đã nghiên cứu tổng quát về thuật toán song song và áp dụng cho một số bài toán về đồ thị. Luận văn cũng đã khái quát các khái niệm về thuật toán song song và các vấn đề liên quan đến thuật toán song song, các mô hình song song, môi trường lập trình song song, lý thuyết đồ thị, cách biểu diễn đồ thị trên máy tính, các vấn đề về đường đi, cây bao trùm trên bảng đồ.
Từ các hiểu biết trên luận văn đã nghiên cứu để song song hóa các thuật toán tìm đường đi ngắn nhất (Dijkstra) và cây bao trùm nhỏ nhất (Prim) từ các thuật toán tuần tự truyền thống.
Ngoài ra do còn thiếu kinh nghiệm trong việc phân tích, thiết kế nên kết quả đạt được còn hạn chế.
Qua nghiên cứu đề tài này cũng đã nắm được các kiến thức về xử lý song song, lập trình song song, lý thuyết đồ thị. Tìm hiểu được cách ứng dụng thuật toán song song và đã áp dụng vào một số bài toán cụ thể.
HƯỚNG PHÁT TRIỂN
Sau khi hoàn thành đề tài tôi sẽ tiếp tục nghiên cứu thêm để phát triển đề tài này, cải tiến thêm các thuật toán và áp dụng vào các lĩnh vực như:
- Áp dụng song song hóa các thuật toán Dijkstra, Prim theo mô hình máy tính phân cụm.
- Nghiên cứu mô hình lập trình song song và áp dụng chuyển các thuật toán tuần tự khác về đồ thị sang thuật toán song song.
- Ứng dụng thực tế vào các bài toán cụ thể trong nhiều lĩnh vực khác.
E:\DỮ LIỆU COP CỦA CHỊ YẾN\DAI HOC DA NANG\HE THONG THONG TIN\NGUYEN DANG KHOA\SAU BAO VE



