

Ứng dụng khai phá dữ liệu xây dựng hệ thống trợ giúp đánh Giá rủi ro trong bảo hiểm tàu cá
Công nghệ thông tin ngày nay đã được ứng dụng rộng khắp trong nhiều lĩnh vực của xã hội trong đó khai phá dữ liệu đã và đang được ứng dụng thành công vào rất nhiều các lĩnh vực khác nhau như: Bảo hiểm, tài chính, y học, giáo dục và viễn thông v.v.
Nền kinh tế ngày càng phát triển thì nhu cầu bảo hiểm càng lớn và các loại hình bảo hiểm ngày càng đa dạng và được hoàn thiện. Bảo hiểm góp phần giữ cho nền kinh tế ổn định, đảm bảo cho cá nhân, gia đình, tổ chức xã hội và các doanh nghiệp luôn duy trì được quá trình hoạt động sản xuất, kinh doanh của mình. Có thể nói, khai thác và đánh bắt cá là một ngành chịu nhiều rủi ro và tổn thất. Ngành này phụ thuộc nhiều vào điều kiện tự nhiên, môi trường hoạt động… Trong quá trình khai thác các ngư dân thường xuyên phải đối mặt với vấn đề rủi ro cho tàu, cho con người, máy móc, ngư lưới cụ. Quảng Ngãi là một tỉnh duyên hải miền Trung có 192 km bờ biển với hơn 5.444 tàu cá và hàng vạn ngư dân tham gia nghề khai thác và đánh bắt cá với sản lượng ước đạt trong năm 2016 là 191.400 tấn. Giải pháp phát triển tàu cá bền vững cũng chính là giải pháp lâu dài để phát triển kinh tế biển, góp phần bảo vệ an ninh và chủ quyền trên biển. Vì vậy bảo hiểm tàu cá là một thị trường đầy hứa hẹn. Đặc biệt, với sự ra đời của ra đời của nghị định 67/2014/NĐ_CP đã tạo điều kiện cho ngư dân đóng mới tàu thuyền mạnh mẽ theo chiều hướng tích cực và thị trường bảo hiểm tàu cá cũng không nằm ngoài luồng chuyển biến đó.
Trong lĩnh vực kinh doanh này, công tác đánh giá rủi ro đối với tàu cá rất quan trọng và hết sức phức tạp. Quy trình tác nghiệp đòi hỏi người thẩm định vừa phải có trình độ chuyên môn nghiệp vụ cao, vừa phải có nhiều kinh nghiệm thực tiễn. Hầu hết các công ty bảo hiểm chỉ chú trọng đến vấn đề doanh thu mà ít quan tâm đến công tác đánh giá rủi ro, đa phần đều đánh giá một cách thủ công sơ sài và cảm tính.
Vì vậy, hiệu quả kinh doanh thường không như mong muốn. Mặt khác, vấn đề giải quyết bồi thường khi có tổn thất xảy ra cần nhanh chóng, đầy đủ và chính xác sẽ mang lại cho khách hàng niềm tin đối với các công ty bảo hiểm. Vấn đề bồi thường sau tai nạn mang tính nhạy cảm rất cao và tác động không nhỏ đến tính hiệu quả của hoạt động kinh doanh bảo hiểm.
Nắm bắt được vấn đề trên cũng như tính cấp thiết của hoạt động đánh giá rủi ro và bồi thường tổn thất trong bảo hiểm tàu cá, tôi thấy cần phải xây dựng triển khai hệ thống ứng dụng công nghệ thông tin nhằm đáp ứng nhu cầu phân tích, xử lý và hỗ trợ đến mức tối đa cho công tác đánh giá và bồi thường rủi ro trong bảo hiểm tàu cá.
Xuất phát từ những lý do trên được sự đồng ý của TS. Nguyễn Trần Quốc Vinh, tôi chọn đề tài: “Ứng dụng khai phá dữ liệu xây dựng hệ thống trợ giúp đánh Giá rủi ro trong bảo hiểm tàu cá” để làm luận văn thạc sỹ.
Mục tiêu nghiên cứu
– Hướng đến là xây dựng hệ thống trợ giúp đánh giá rủi ro cho tàu cá, đảm bảo đầy đủ các yêu cầu về mặt chuyên môn trong lĩnh vực bảo hiểm tàu cá và hướng đến nâng cao hiệu quả kinh doanh trong đơn vị.
– Nêu bật những vấn đề hạn chế, đề xuất giải pháp khắc phục những tồn tại. giúp tăng cường năng lực cạnh trạnh với các đối thủ trên thị trường bảo hiểm tàu cá.
– Thu thập dữ liệu trong lĩnh vực bảo hiểm tàu cá tại Quảng Ngãi.
– Tìm hiểu các thuật toán phân lớp C4.5 và rừng ngẫu nhiên (random forest) và so sánh độ chính xác trên tập dữ liệu bảo hiểm tàu cá thu thập được.
– Phân tích, thiết kế và phát triển hệ thống trợ giúp đánh giá rủi ro bảo hiểm tàu cá trên cơ sở thuật toán phân lớp được chọn.
Đối tượng và phạm vi nghiên cứu
– Quy trình đánh giá rủi ro tàu cá.
– Các vấn đề liên quan đến độ rủi ro trong bảo hiểm tàu cá.
– Hồ sơ khách hàng tham gia mua bảo hiểm tàu cá
– Các kỹ thuật khai phá dữ liệu.
– Kỹ thuật khai phá dữ liệu cây quyết định C4.5, rừng ngẫu nhiên (Random Forrest).
– Số liệu kinh doanh của Công ty Cổ phần Bảo Minh tại Quảng Ngãi trong khoảng thời gian 2015, 2016.
– Khai phá dữ liệu và phân lớp dữ liệu.
– Giải thuật xây dựng cây quyết định.
– Nghiên cứu về Thuật toán C4.5 và rừng ngẫu nhiên trong việc dự đoán và phân loại thông tin.
– Tiến hành thu thập và tổng hợp các tài liệu liên quan đến quy trình thẩm định và đánh giá hồ sơ đối với lĩnh vực bảo hiểm tàu cá
– Vận dụng các cơ sở lý thuyết để xây dựng ứng dụng, tiến hành kiểm thử so sánh đánh giá hiệu suất của ứng dụng.
Dự kiến kết quả
– Hiểu thêm được phương pháp khai phá dữ liệu và ứng dụng phương pháp khai phá dữ liệu vào dự đoán tính rủi ro trong khai thác bảo hiểm nhằm nâng cao hiệu quả kinh doanh trong đơn vị.
– Xây dựng hệ thống hỗ trợ đánh giá rủi ro cho tàu cá tại Công ty Cổ phần bảo hiểm Bảo Minh tại Quảng Ngãi.
– Hệ thống giúp đánh giá rủi ro nhanh chóng nhưng vẫn đảm bảo về mặt tối ưu, có chức năng cơ bản và dễ sử dụng.
Ý nghĩa khoa học và thực tiễn của luận văn
Áp dụng lý thuyết về khai phá dữ liệu phân vào bài toán đánh giá rủi ro trong khai thác bảo hiểm cho tàu cá .
Về mặt thực tiễn, ứng dụng có khả năng phân tích dữ liệu kinh doanh của công ty trong những năm gần đây và qua đó có khả năng phát hiện ra các trường hợp bảo hiểm tàu cá có mức độ rủi ro cao.
Giúp cho việc dự đoán nhằm hỗ trợ ra quyết định một cách khoa học, tránh được các tình huống bồi thường theo cảm tính, hạn chế các trường hợp rủi ro và tăng hiệu quả kinh doanh của công ty.
Chương 1: Nghiên cứu tổng quan
Chương này, tôi trình bày các cơ sở lý thuyết tổng quan về khai phá dữ liệu, các kỹ thuật khai phá dữ liệu. Giới thiệu về cây quyết định trong phân lớp dữ liệu. Giải thuật C4.5 và Random Forest.
Chương 2: Ứng dụng cây quyết định trong công tác đánh giá rủi ro và bồi thường bảo hiểm tàu cá
Chương này, tôi sẽ tìm hiểu và phân tích hiện trạng tại đơn vị, nêu lên những vấn đề hạn chế và đề xuất giải pháp khắc phục. So sánh và đánh giá phân lớp giữa 2 thuật toán C4.5 và Random Forest. Ứng dụng để xây dựng mô hình phân lớp dữ liệu để giải quyết bài toán đặt ra.
Chương 3: Xây dựng và thử nghiệm ứng dụng
Tôi tập trung trình bày chi tiết về mô hình kiến trúc tổng thể của hệ thống và xây dựng ứng dụng. Tiến hành thử nghiệm trên số liệu thực tế, sau đó đánh giá kết quả đạt được và khả năng triển khai ứng dụng trên toàn hệ thống.
Cuối cùng là những đánh giá, kết luận và hướng phát triển của đề tài.

CHƯƠNG 1
NGHIÊN CỨU TỔNG QUAN
1.1. Tổng quan về khai phá dữ liệu
1.1.1. Sơ lược về khai phá dữ liệu
Khai phá dữ liệu là một lĩnh vực khoa học ra đời vào những năm cuối thập kỷ 80 của thế kỷ XX, nhằm khai thác những thông tin, tri thức hữu ích, tiềm ẩn trong các cơ sở dữ liệu (CSDL) của các tổ chức, doanh nghiệp… Cùng với sự phát triển vượt bật của công nghệ thông tin, các hệ thống thông tin có thể lưu trữ một khối lượng lớn dữ liệu về hoạt động hàng ngày của chúng. Từ khối dữ liệu này, các kỹ thuật trong khai phá dữ liệu (KPDL) và máy học (MH) có thể dùng để trích xuất những thông tin hữu ích mà chúng ta chưa biết. Các tri thức vừa học được có thể vận dụng để cải thiện hiệu quả hoạt động của hệ thống thông tin ban đầu.
Khái niệm khai phá dữ liệu là “quá trình khảo sát và phân tích một lượng lớn các dữ liệu được lưu trữ trong các CSDL, kho dữ liệu… để từ đó trích xuất ra các thông tin quan trọng, có giá trị tiềm ẩn bên trong”.
1.1.2. Các kỹ thuật áp dụng trong khai phá dữ liệu
Học có giám sát: Là quá trình gán nhãn lớp cho các phần tử trong CSDL dựa trên một tập các ví dụ huấn luyện và các thông tin về nhãn lớp đã biết.
Học không có giám sát: Là quá trình phân chia một tập dữ liệu thành các lớp hay cụm dữ liệu tương tự nhau mà chưa biết trước các thông tin về lớp hay tập các ví dụ huấn luyện.
Học nửa giám sát: Là quá trình phân chia một tập dữ liệu thành các lớp dựa trên một tập nhỏ các ví dụ huấn luyện và các thông tin về một số nhãn lớp đã biết trước.
1.1.3. Các bước xây dựng hệ thống khai phá dữ liệu
1.1.4. Ứng dụng của khai phá dữ liệu
1.1.5. Khó khăn trong khai phá dữ liệu
1.2. Phân lớp trong khai phá dữ liệu
1.2.1. Phân lớp dữ liệu
Phân lớp dữ liệu là gán các mẫu mới vào các lớp với độ chính xác cao nhất để dự báo cho các bộ dữ liệu (mẫu) mới.
Đầu vào là một tập các mẫu dữ liệu huấn luyện, với một nhãn phân lớp cho mỗi mẫu dữ liệu. Đầu ra là mô hình dự đoán (bộ phân lớp) dựa trên tập huấn luyện và những nhãn phân lớp.
1.2.2. Quá trình phân lớp dữ liệu
Bước thứ nhất (learning): quá trình học nhằm xây dựng một mô hình mô tả tập các lớp dữ liệu hay các khái niệm định trước.
Bước thứ hai (classification): bước này dùng mô hình đã xây dựng được ở bước thứ nhất để phân lớp dữ liệu mới.
1.2.3. Các vấn đề liên quan đến phân lớp dữ liệu
1.3. Giới thiệu cây quyết định
1.3.1. Giới thiệu chung
1.3.2. Ưu điểm của cây quyết định
1.3.3. Các luật được rút ra từ cây quyết định
1.4. Thuật toán C4.5
1.4.1. Giới thiệu
Giải thuật C4.5 biểu diễn các khái niệm ở dạng các cây quyết định. Biểu diễn này cho phép chúng ta xác định phân loại của một đối tượng bằng cách kiểm tra các giá trị của nó trên một số thuộc tính nào đó.
Đầu vào: Một tập hợp các ví dụ. Mỗi ví dụ bao gồm các thuộc tính mô tả một tình huống, hay một đối tượng nào đó, và một giá trị phân loại của nó.
Đầu ra: Cây quyết định có khả năng phân loại đúng đắn các ví dụ trong tập dữ liệu huấn luyện, và hy vọng là phân loại đúng cho cả các ví dụ chưa gặp trong tương lai.
1.4.2. Giải thuật C4.5 xây dựng cây quyết định từ trên xuống
1.4.3. Chọn thuộc tính phân loại tốt nhất
1.4.4. Entropy đo tính thuần nhất của tập ví dụ
Khái niệm entropy của một tập S được định nghĩa trong lý thuyết thông tin là số lượng mong đợi các bit cần thiết để mã hóa thông tin về lớp của một thành viên rút ra một cách ngẫu nhiên từ tập S. Trong trường hợp tối ưu, mã có độ dài ngắn nhất. Theo lý thuyết thông tin, mã có độ dài tối ưu là mã gán –log2p bit cho thông điệp có xác suất là p.
Trong trường hợp S là tập ví dụ, thì thành viên của S là một ví dụ, mỗi ví dụ thuộc một lớp hay có một giá trị phân loại.
Entropy có giá trị nằm trong khoảng [0..1].
Entropy(S) = 0: tập ví dụ S chỉ toàn thuộc cùng một loại, hay S là thuần nhất.
Entropy(S) = 1: tập ví dụ S có các ví dụ thuộc các loại là bằng nhau.
0 < Entropy(S) < 1: tập ví dụ S có số lượng ví dụ thuộc các loại khác nhau là không bằng nhau.
Tập S là tập dữ liệu huấn luyện, trong đó thuộc tính phân loại có hai giá trị, giả sử là âm (-) và dương (+). Trong đó:
p+ là phần các ví dụ dương trong tập S.
p_ là phần các ví dụ âm trong tập S.
Khi đó, entropy đo độ pha trộn của tập S theo công thức sau:
Entropy(S) = -p+ log2 p+ – p– log2 p–
Công thức Entropy tổng quát là:
Entropy là số đo độ pha trộn của một tập ví dụ, bây giờ chúng ta sẽ định nghĩa một phép đo hiệu suất phân loại các ví dụ của một thuộc tính. Phép đo này gọi là lượng thông tin thu được (hay độ lợi thông tin), nó đơn giản là lượng giảm entropy mong đợi gây ra bởi việc phân chia các ví dụ theo thuộc tính này.
Một cách chính xác hơn, Gain(S, A) của thuộc tính A, trên tập S, được định nghĩa như sau:
Giá trị Value (A) là tập các giá trị có thể cho thuộc tính A, và Sv là tập con của S mà A nhận giá trị v.
1.4.5. Tỷ suất lợi ích Gain Ratio
Thuật toán C4.5, một cải tiến của ID3, mở rộng cách tính Information Gain thành Gain Ratio để cố gắng khắc phục sự thiên lệch.
Gain Ratio được xác định bởi công thức sau:
Trong đó, SplitInformation(S, A) chính là thông tin do phân tách của A trên cơ sở giá trị của thuộc tính phân loại S. Công thức tính như sau:
1.4.6. Chuyển cây về dạng luật
1.5. Random Forest
1.5.1. Cơ sở và định nghĩa
Random Forest là một phương pháp học quần thể để phân loại, hồi quy và các nhiệm vụ khác, hoạt động bằng cách xây dựng vô số các cây quyết định trong thời gian đào tạo và đầu ra của lớp là mô hình phân lớp hoặc hồi quy của những cây riêng biệt. Nó như là một nhóm phân loại và hồi quy cây không cắt tỉa được làm từ các lựa chọn ngẫu nhiên của các mẫu dữ liệu huấn luyện. Tính năng ngẫu nhiên được chọn trong quá trình cảm ứng. Dự đoán được thực hiện bằng cách kết hợp (đa số phiếu để phân loại hoặc trung bình cho hồi quy) dự đoán của quần thể.
1.5.2. Tóm tắt giải thuật
Đầu vào: là tập dữ liệu đào tạo.
Đầu ra: là mô hình Random Forest, Random Forest là tập hợp nhiều cây quyết định n tree.
Với mỗi Cây n tree được xây dựng bằng các sử dụng thuật toán sau:
Với N là số lượng các trường hợp của dữ liệu đào tạo, M là số lượng các biến trong việc phân loại.
Lấy m là số các biến đầu vào được sử dụng để xác định việc phân chia tại 1 Nút của cây, m < M.
Chọn 1 tập huấn luyện cho cây bằng cách chọn n ngẫu nhiên với sự thay thế từ tất cả các trường hợp đào tạo có sẵn N. Sử dụng các phần còn lại để ước lượng các lỗi của cây, bằng cách dự đoán các lớp của chúng.
Với mỗi nút của cây, chọn ngẫu nhiên m là cơ sở phân chia tại nút đó (độc lập với mỗi nút). Tính chia tốt nhất dựa trên các biến m trong tập huấn luyện n.
Mỗi cây được trồng hoàn toàn và không tỉa (có thể được sử dụng trong vệ xây dựng một bộ phân loại như các cây bình thường).
Đối với mỗi dự đoán mới được đưa vào. Nó được gán nhãn của mẫu đạo tạo trong các nút cuối để kết thúc. Thủ tục sẽ được lập lại qua tất cả các cây Ntree, và số phiếu bình chọn (với phân lớp) hay trung bình (với hồi quy) của các cây Ntree là dự đoán của rừng ngẫu nhiên.
1.5.3. Mô hình phân lớp với Random Forest
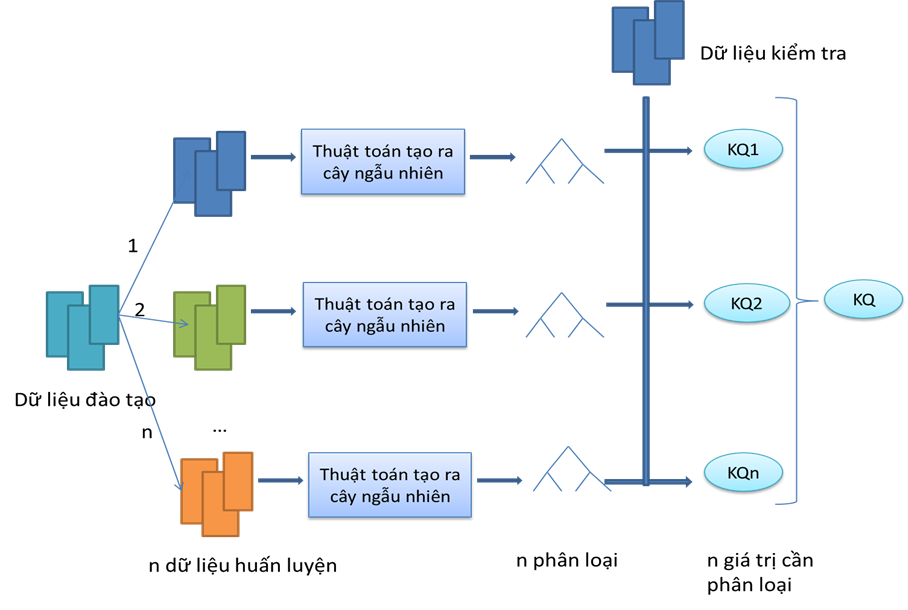
Hình 1.1. Mô hình phân lớp với Random Forest
1.5.4. Tạo ra n tập dữ liệu huấn luyện bằng cách sử dụng Bootstrap
1.5.5. Xây dựng cây ngẫu nhiên
1.5.6. Tạo cây ngẫu nhiên
1.5.7. Đặc điểm của Random Forest
CHƯƠNG 2
ỨNG DỤNG CÂY QUYẾT ĐỊNH TRONG CÔNG TÁC ĐÁNH GIÁ RỦI RO VÀ BỒI THƯỜNG BẢO HIỂM TÀU CÁ
2.1. Khái quát về thị trường bảo hiểm tàu cá
2.2. Đánh giá rủi ro tàu cá
2.2.1. Khái niệm rủi ro
2.2.2. Khái niệm về đánh giá rủi ro
2.2.3. Phạm vi bảo hiểm
2.2.4. Quy trình đánh giá rủi ro trong bảo hiểm tàu cá
2.2.5. Các yếu tố ảnh hưởng đến rủi ro trong bảo hiểm tàu cá
2.3. Phân tích hiện trạng
2.3.1. Chỉ số trong lĩnh vực kinh doanh bảo hiểm tàu cá
2.3.2. Giải pháp xây dựng hệ thống trợ giúp đánh giá rủi ro trong bảo hiểm tàu cá
2.4. So sánh kết quả phân lớp giữa 2 thuật toán C4.5 và Random Forest
2.4.1. Ứng dụng thuật toán C4.5
2.4.2. Ứng dụng Random Forresst
2.4.2.1. Phân tích dữ liệu
Có rất nhiều yếu tố ảnh hưởng đến tỉ lệ rủi ro trong bảo hiểm tàu cá. Tuy nhiên ở đây, chúng ta chú trọng phân tích các tập thuộc tính với những yếu tố chính trong bảng dữ liệu như sau:
Bảng 2.3. Bảng dữ liệu mẫu của 10 khách hàng
| Các thuộc tính | Thuộc tính phân loại | |||||||
| TT | Mục Đích sử dụng | Thời gian sử dụng | Kinh nghiệm lái tàu | Làm nước | Số tiền bồi thường | Khu vực để tàu | Phạm vi hoạt đông | Rủi ro |
| 1 | Giả cào | 6 | 3 | Có | 10 | Cầu cảng | Gần bờ | THẤP |
| 2 | Câu | 8 | 7 | Không | 30 | Không | Gần bờ | TB |
| 3 | Giả cào | 14 | 6 | Không | 50 | Không | Gần bờ | CAO |
| 4 | Lặn | 11 | 6 | Có | 10 | Cầu cảng | Xa bờ | TB |
| 5 | Giả cào | 12 | 11 | Có | 20 | Cầu cảng | Gần bờ | TB |
| 6 | Giả cào | 12 | 12 | Không | 50 | Không | Xa bờ | CAO |
| 7 | Lặn | 7 | 2 | Có | 10 | Cầu cảng | Gần bờ | THẤP |
| 8 | Câu | 6 | 4 | Không | 40 | Không | Xa bờ | TB |
| 9 | Giả cào | 14 | 7 | Không | 50 | Không | Xa bờ | TB |
| 10 | Giả cào | 9 | 4 | Không | 50 | Cầu cảng | Gần bờ | CAO |
Trong đó:
Thuộc tính Mục đích sử dụng là loại thộc tính Nominal có giá trị [giả cào, lặn, câu]
+ Giả cào: Là tàu sử dụng lưới để đánh bắt cá
+ Lặn: Là tàu sử dụng con người lặn để đánh bắt cá…
+ Câu: Là tàu sử dụng lưỡi câu để đánh bắt cá …
Thuộc tính Thời gian sử dụng là loại thuộc tính Numeric có giá trị [3, 6, 9, 12] nếu tàu đóng nằm trong thời gian từ 1 năm đến 3 năm thì có giá trị bằng <=3 và là tàu có rủi ro là thấp nhất. Ngược lại, tàu sản xuất >3 thì nguy cơ rủi ro càng cao.
Thuộc tính Kinh nghiệm lái tàu là loại thuộc tính Numeric có giá trị [3, 6, 9, 12] nếu kinh nghiệm lái tàu >3 thì nguy cơ rủi ro thấp. Ngược lại kinh nghiệm lái <=3 thì nguy cơ rủi ro càng cao.
Thuộc tính làm nước là loại thộc tính Nominal có giá trị [Có, Không] nếu chủ tàu thường xuyên bảo dưỡng, kiểm tra định kỳ, thì chắc chắn sẽ giảm thiểu được rủi ro.
Thuộc tính Khu vực để tàu là loại thộc tính Nominal có giá trị [Cầu cảng, Không] đây cũng là yếu tố ảnh hưởng đến mức độ rủi ro của tàu tham gia bảo hiểm. Vì nếu tàu không có cầu cảng, thì nguy cơ va quẹt tàu nơi đậu đỗ là rất cao
Thuộc tính Số tiền bồi thường là loại thuộc tính Numeric có giá trị [20, 30, 40, 50] nếu số tiền bồi thường <=40 thì có mức độ rủi ro thấp hơn những tàu có số tiền bồi thường >40
Thuộc tính Phạm vi hoạt động là loại thộc tính Nominal có giá trị [gần bờ, xa bờ] nếu tàu hoạt động trên vùng biển xa bờ. Thì khả năng gặp rủi ro càng cao. Ngược lại nếu tàu hoạt động ở vùng biển gần bờ thì nguy cơ rủi ro là thấp.
Trong đó:
+ Numeric: Là các giá trị số hay giá trị liên tục.
+ Nominal: Là các giá trị định danh hay giá trị không liên tục.
Các yếu tố trên chính là các tập thuộc tính, dựa vào tập thuộc tính này ta sẽ dự đoán giá trị cho thuộc tính đích rủi ro. Đây là thuộc tính phân loại.
2.4.2.2. Xây dựng mô hình phân lớp với Random Forest
Xây dựng mô hình phân lớp với dữ liệu đầu vào là bảng dữ liệu của 1724 hồ sơ khách hàng với 9 thuộc tính và thuộc tính cần phân lớp là: RỦI RO, như sau:
Trước hết xác định 2 giá trị quan trọng của Random Forest là numTree (số cây của rừng) và numFeatures (số biến được lựa chọn để chia nút).
Ta xây dựng Random Forest gồm numTree cây phân lớp.
Mỗi cây phân lớp được xây dựng với các bước sau:
Dữ liệu đào tạo [1724 khách hàng]
Dữ liệu huấn luyện
[1724 khách hàng]
OOB [410 khách hàng]
Bước 1: Tạo tập huấn luyện bằng các sử dụng bootstrap
Bước 2: Xây dựng một cây quyết định ngẫu nhiên
?
?
?
Thuộc tính
Hình 2.2. Cấu trúc cây ngẫu nhiên
Bước 3: Chọn nút chia tốt nhất bằng cách tính theo giá trị GAIN. Lập lại như vậy với mỗi nút cho đến khi cây không thể chia nữa.
Cuối cùng ta được Random Forest với numTree cây.
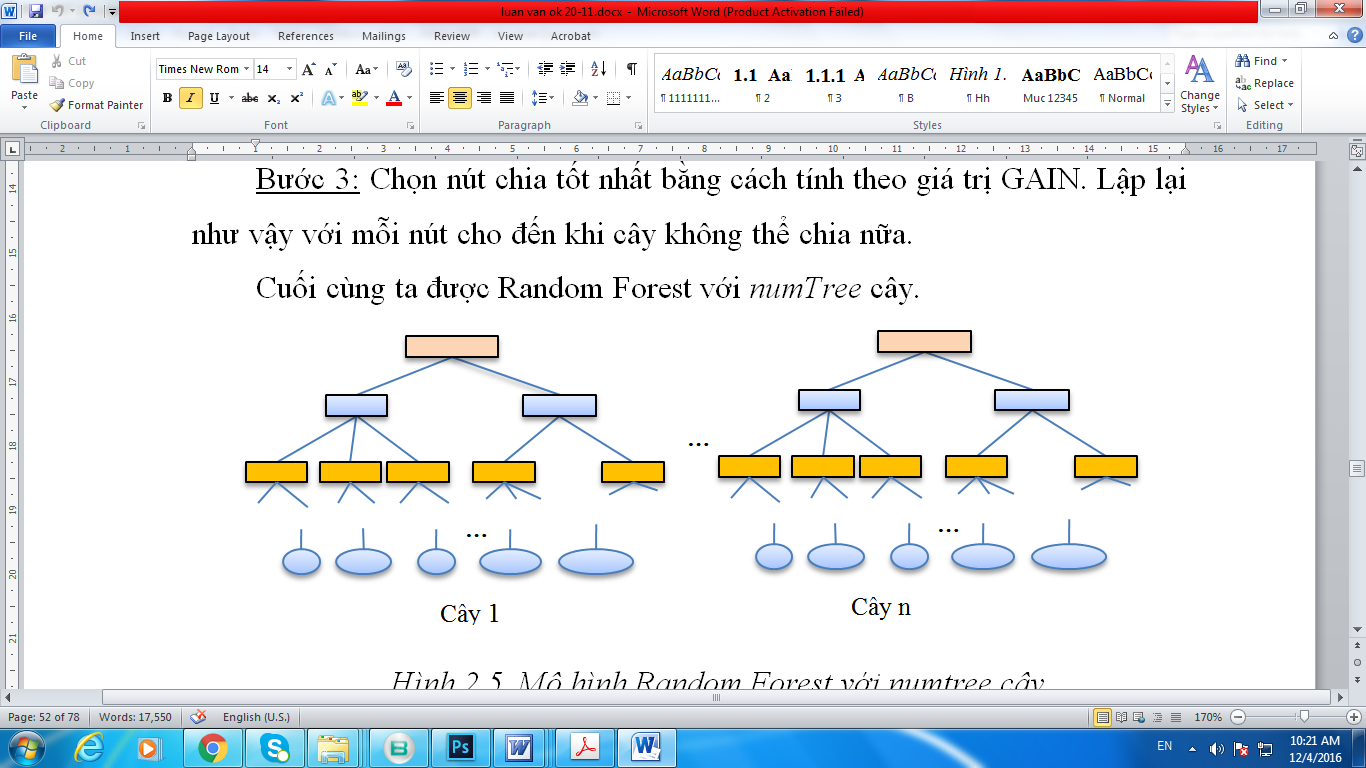
Hình 2.3. Mô hình Random Forest với numtree cây
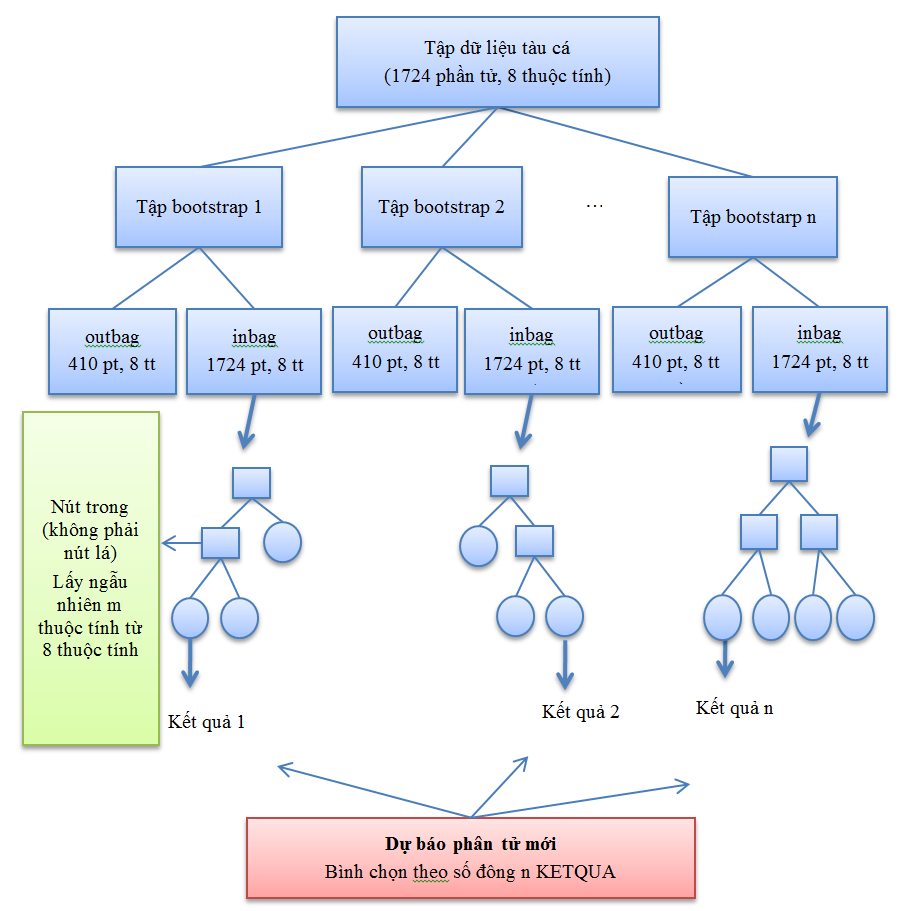
Hình2.4. Mô hình tổng quát của Random Forest để phân lớp
2.4.2.3. Ước tính độ chính xác của mô hình
| Dữ liệu | Số lượng bảng ghi | Thuộc tính | Ramdon Forest | C4.5 | ||
| Trường hợp Phân loại chính xác | Trường hợp Phân loại không chính xác | Trường hợp Phân loại chính xác | Trường hợp Phân loại không chính xác | |||
| Bảo hiểm tàu cá | 1724 | 8 | 97.66% | 2.33% | 96.92% | 3.07% |
So sánh C4.5 và Random Forest
Thực hiện so sánh và đánh giá trên phần mềm Weka với phương pháp đánh giá độ chính xác bằng 10-fold croos validation
Kết quả trên cho thấy phần lớn phương pháp sử dụng thuật toán Random Forest cho kết quả chính xác cao hơn. Đặc biệt với bộ dữ liệu càng lớn thì Random Forest cho kết quả chính xác tốt hơn, còn đối với phương pháp sử dụng thuật toán C4.5 (J-48 được cắt tỉa) thì lại tiện dụng với bộ dữ liệu nhỏ.
CHƯƠNG 3
XÂY DỰNG VÀ THỬ NGHIỆM ỨNG DỤNG
3.1. Chức năng hệ thống
3.1.1. Phân tích yêu cầu
Biểu đồ ca sử dụng
Biểu đồ hoạt động
Biểu đồ tuần tự
3.1.2. Các chức năng chính
Hệ thống xây dựng gồm các chức năng cơ bản sau:
Lựa chọn nguồn dữ liệu:
Tiền xử lý dữ liệu:
Xây dựng cây quyết định:
Chuyển cây về dạng luật:
Thống kê tỉ lệ lỗi:
3.2. Thử nghiệm ứng dụng
- Giao diện đăng nhập hệ thống: Người dùng đăng nhập với tên đăng nhập và mật khẩu riêng để đăng nhập vào hệ thống.
Hình 3.1. Màn hình Đăng nhập hệ thống
- Giao diện chính: Có 2 chức năng đó là Huấn Luyện Dữ Liệu và Tư Vấn:
- Huấn Luyện Dữ Liệu: Đầu tiên ta chon mút Chọn dữ liệu để nạp dữ liệu huấn luyện (dữ liệu huấn luyện là file excel có phần mở rộng là CSV)
Mô hình hệ thống phân lớp Random Forest. Sau khi chay hệ thống sẽ sinh ra các tập luật và kết xuất ra kết quả dự đoán khách hàng và lưu trong database.
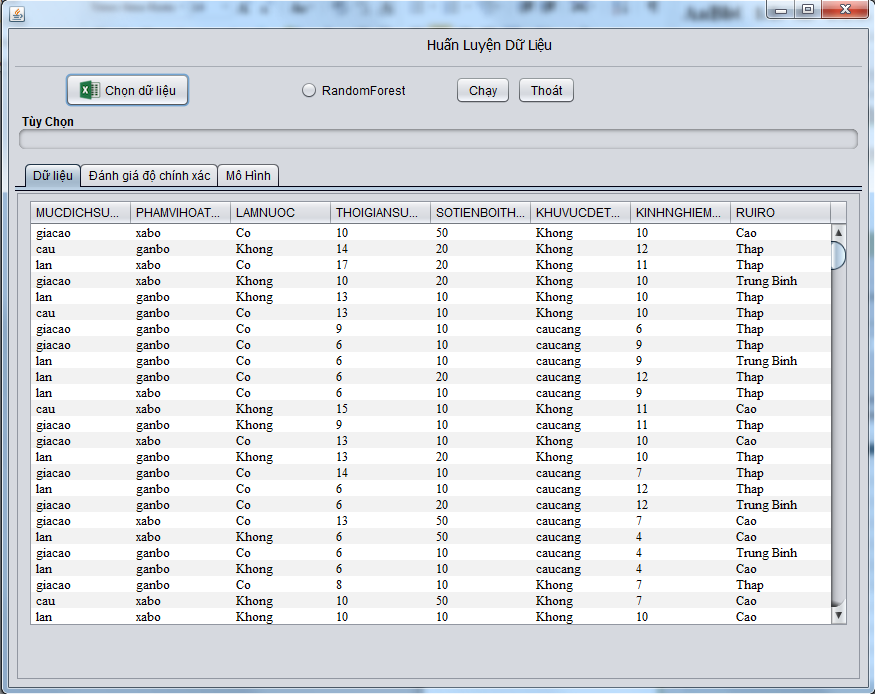
Hình 3.3. Màn hình tải dữ liệu huấn luyện
- Mô hình phân lớp với Random Forest
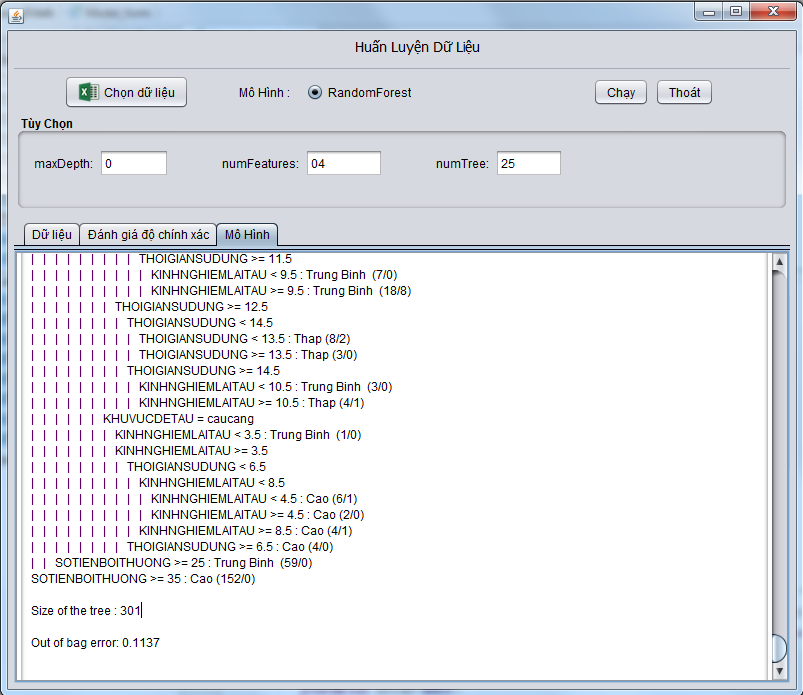
Hình 3.4. Giao diện mô hình phân lớp Random Forest
- Giao diện Tư Vấn: Khi chọn chức năng này, hệ thống cho phép người dùng cập nhật trực tiếp các thông tin của khách hàng mà cán bộ thậm định cần hệ thống tư vấn tư vấn, sau đó click Xem Kết Quả, hệ thống sẽ dựa vào tập luật đã có trong database và xuất kết quả dự đoán phân lớp khách hàng trong vùng hiện thị Kết Quả.
Hình 3.6. Giao diện ứng dụng tư vấn
3.3. Đánh giá độ chính xác
3.3.1. Kết quả mô hình phân lớp với Random Frorest:
Đánh giá độ chính xác của mô hình
Đánh giá độ chính xác của mô hình bằng cách sử dụng k-fold croos validation với k=10 Kết quả với mỗi lần chạy là:
Fold 1:
**Ket Qua**
STT PhanLop DuDoan
1 TrungBinh Thap
2 Cao Cao
3 TrungBinh TrungBinh
4 Cao Cao
.
.
.
172 TrungBinh TrungBinh
173 Thap Thap
Số dự đoán chinh xác là: 146.0/173.0
Độ Chính Xác : 84.39306358381504%
Hình 3.9. Độ chính xác của mô hình Random Forest- fold1
************** TỔNG KẾT ******************
Số trường hợp chính xác của Random Forests với 1724 trường hợp = 1472.0
Tỉ lệ chính xác của Random Forests = 85.38283062645012%
***************************************
1. Kết quả đã đạt được
Về lý thuyết, luận văn đã trình bày được cơ sở lý thuyết liên quan đến khai phá dữ liệu, các bước xây dựng hệ thống khai phá dữ liệu và đã trình bày được phân lớp dữ liệu với thuật toán cây quyết định C4.5 và Random Forest
Đã phân tích được hiện trạng và các yếu tố ảnh hưởng đến rủi ro trong bảo hiểm
tàu cá. Phân tích đã trình bày chi tiết quá trình tính toán, chọn lựa thuộc tính để xây dựng cây quyết định với thuật toán C4.5 và Random Forest có khả năng phân loại đúng đắn từ tập dữ liệu về tàu cá. Từ đó so sánh kết qua phân lớp giữa 2 thuật toán C4.5 và Random Foresst trên Weka cho thấy phần lớn thuật toán Random Forest cho kết quả chính xác cao hơn
Từ kết quả so sánh này luận văn đã xây dựng một hệ thống trợ giúp đánh giá rủi ro cho bảo hiểm tàu cá bắng thuật toán Random Forest đáp ứng đầy đủ các yêu cầu chuyên môn. Giúp cho người dùng ra quyết định một cách khoa học, tránh được các tình huống thẩm định theo cảm tính, hạn chế các trường hợp rủi ro và tạo thế mạnh cạnh tranh đối với các doanh nghiệp trong lĩnh vực bảo hiểm.
2. Hạn chế
Chương trình phải chuyển đổi dữ liệu từ SQL Server sang Excel. Nên chỉ xử lý dữ liệu được lưu trữ bằng các tập tin Excel.
Chưa kết nối và truy xuất dữ liệu trực tiếp đến hệ quản trị cơ sở dữ liệu SQL Server của công ty.
Dữ liệu có độ nhiễu hoặc một số thuộc tính thiếu giá trị. Sẽ phát sinh những trường hợp phân lớp hay phân loại bị sai.
3. Hướng phát triển
Tiếp tục nghiên cứu các thuật toán khai phá dữ liệu bằng cây quyết định như thuật toán CHAID, thuật toán MARS, thuật toán ADTNDA (dựa vào độ phụ thuộc mới của thuộc tính) để nâng cao hiệu quả mô hình cây quyết định. Cần thử nghiệm hệ thống với khối lượng dữ liệu lớn để đánh giá lại độ tin cậy của cây quyết định đánh giá rủi ro.
Xây dựng giao diện đồ họa trực quan hơn để dễ dàng tương tác với người dùng.
E:\DỮ LIỆU COP CỦA CHỊ YẾN\DAI HOC DA NANG\HE THONG THONG TIN\NGUYEN PHUONG NAM



