

Ứng dụng khai phá dữ liệu xây dựng hệ thống trợ giúp phòng chống và giảm nhẹ rủi ro thiên tai tại trường học
Ngày nay cùng với sự thay đổi và phát triển không ngừng của ngành Công nghệ thông tin nói chung và trong các ngành công nghệ phần cứng, phần mềm và hệ thống các dữ liệu phục vụ trong các lĩnh vực kinh tế – xã hội nói riêng, thì việc thu thập thông tin cũng như nhu cầu lưu trữ thông tin ngày càng lớn. Bên cạnh đó việc tin học hóa một cách nhanh chóng các hoạt động sản xuất, kinh doanh cũng như nhiều lĩnh vực hoạt động khác đã tạo ra cho chúng ta một lượng dữ liệu lớn. Rất nhiều cơ sở dữ liệu (CSDL) đã được sử dụng trong các hoạt động sản xuất, kinh doanh, quản lí…
Những ứng dụng thành công trong khám phá tri thức cho thấy khai phá dữ liệu là một lĩnh vực phát triển bền vững mang lại nhiều lợi ích và có nhiều triển vọng, đồng thời có ưu thế hơn hẵn so với các công cụ phân tích dữ liệu truyền thống. Data mining có nhiều hướng quan trọng và hai trong số đó là phân cụm dữ liệu (Data Clustering) và luật kết hợp (Association Rule). Phân cụm dữ liệu là quá trình tìm kiếm để phân ra các cụm dữ liệu, các mẫu dữ liệu từ khối dữ liệu lớn, luật kết hợp là tìm ra các mối quan hệ giữa các đối tượng trong khối dữ liệu lớn.
Phân cụm dữ liệu và luật kết hợp là những kỹ thuật để khai thác dữ liệu có hiệu quả. Phân cụm dữ liệu và luật kết hợp đã được ứng dụng trong nhiều lĩnh vực khác nhau như: kinh tế, bảo hiểm, quy hoạch đô thị, du lịch…Tuy nhiên trong lĩnh vực giáo dục và nhất là khía cạnh dự báo nguy cơ rủi ro thiên tai tại trường học vẫn chưa được khai thác hiệu quả.
Trong những năm qua đã có nhiều chương trình và hoạt động hỗ trợ trường học và trẻ em ứng phó với thiên tai. Tuy nhiên các chương trình chỉ tập trung vào các hoạt động lồng ghép kiến thức giảm nhẹ rủi ro thiên tai vào bài giảng các môn học chính khóa như sinh học, vật lí, địa lí …và trong hoạt động ngoại khóa như các cuộc thi tìm hiểu kiến thức về thiên tai, câu lạc bộ, diễn đàn, mà chưa có công cụ thu thập thông tin và phân tích dữ liệu trường học để đưa ra dự đoán các nguy cơ rủi ro, thiệt hại nếu có thiên tai xảy ra. Xuất phát từ nhu cầu thực tế đó nên tôi chọn vấn đề: “Ứng dụng khai phá dữ liệu xây dựng hệ thống trợ giúp phòng, chống và giảm nhẹ rủi ro thiên tai tại trường học” làm đề tài luận văn thạc sĩ của mình.
2. Mục đích và nhiệm vụ của đề tài
2.1. Mục đích
Xây dựng hệ thống giúp các cơ sở giáo dục có cơ sở:
Lập kế hoạch phòng, tránh và giảm nhẹ rủi ro nếu có thiên tai xảy ra.
Xác định những thiên tai đã và có nguy cơ xảy ra tại các khu vực ở gần các cơ sở giáo dục.
Chuẩn bị nhân lực, vật lực, phương tiện trang thiết bị và nhu cầu yếu phẩm phục vụ ứng phó thiên tai.
Nâng cấp, sửa chữa, bổ sung cơ sở vật chất, phòng ốc cần thiết để phòng, tránh và giảm nhẹ rủi ro nếu có thiên tai xảy ra.
Có những đánh giá, dự báo chính xác thiệt hại nếu có thiên tai xảy ra.
Báo cáo kịp thời lên cấp trên trước, trong và sau khi thiên tai xảy ra.
2.2. Nhiệm vụ
Để đạt được những mục đích nêu trên, nhiệm vụ của tôi là nghiên cứu những nội dung sau:
- Thu thập thông tin trường học bao gồm: Vị trí của nhà trường, cơ sở vật chất của nhà trường, số liệu thống kê cán bộ giáo viên, nhân viên và học sinh, những rủi ro trên đường tới trường, các loại phòng học của nhà trường, tình hình giáo dục phòng, chống giảm nhẹ thiên tai… (Bộ công cụ thu thập các thông tin này được xây dựng dựa vào các tiêu chí đánh giá trường học an toàn).
- Nghiên cứu các kỹ thuật phân cụm và luật kết hợp khai phá dữ liệu thu thập được, đưa ra các nhóm nguy cơ rủi ro thiên tai và dự đoán các rủi ro có thể gặp phải khi thiên tai xảy ra.
– Cài đặt triển khai hệ thống.
3. Đối tượng và phạm vi nghiên cứu
3.1. Đối tượng nghiên cứu
Thông tin về vị trí trường, các điều kiện về cơ sở vật chất và các thông tin khác liên quan đến việc thu thập thông tin của các cơ sở giáo dục trên địa bàn tỉnh Kon Tum.
Thuật toán phân cụm dữ liệu, thuật toán luật kết hợp (sử dụng 2 thuật toán chính là K_means và Apriori để cài đặt chương trình).
Công cụ khai phá dữ liệu Business Intelligence Development Studio (BIDS), ngôn ngữ lập trình Visual C# và hệ quản trị CSDL SQL.
3.2. Phạm vi nghiên cứu
Nghiên cứu thu thập thông tin các trường trên địa bàn tỉnh Kon Tum gồm (16 trường Trung học phổ thông, 10 trường Phổ thông dân tộc nội trú, 07 Trung tâm giáo dục thường xuyên, 103 trường Trung học cơ sở, 142 trường Tiểu học, 121 trường Mầm non).
Thu thập thông tin về cơ sở vật chất, vị trí địa lí, điều kiện tự nhiên xung quanh các trường học như núi, sông, suối…
4. Phương pháp nghiên cứu
Phân tích, so sánh và đối chiếu.
Thu thập tổng hợp thông tin
Kiểm thử phần mềm.
Đánh giá kết quả đạt được.
5. Giải pháp đề xuất
Mô tả hệ thống:
Đầu vào: Thu thập các thông tin về trường học, cơ sở vật chất, vị trí địa lí của trường, vị trí địa lí khu vực gần trường, những nguy cơ rủi ro trên đường tới trường, thông tin về học sinh, cán bộ, giáo viên, nhân viên…(Bộ công cụ thu thập các thông tin này được xây dựng dựa vào các tiêu chí đánh giá trường học an toàn).
Đầu ra: Dự báo mức độ nguy cơ rủi ro khi có thiên tai xảy ra ở các trường, nhóm các trường có khả năng chống chịu thiên tai gần giống nhau.
6. Kết cấu luận văn
Ngoài các phần mở đầu, mục lục, danh mục hình, kết luận và tài liệu tham khảo luận văn chia làm 3 chương:
Chương 1: Tổng quan về kỹ thuật phát hiện tri thức và khai phá dữ liệu
Chương này giới thiệu một cách tổng quát về quá trình khám phá tri thức nói chung và khám phá dữ liệu nói riêng. Các phương pháp, lĩnh vực và các hướng tiếp cận trong khai phá dữ liệu.
Chương 2: Tìm hiểu phân cụm dữ liệu, luật kết hợp, thuật toán K_means và thuật toán Apriori
Trong chương này trình bày khái niệm và mục tiêu phân cụm dữ liệu và luật kết hợp, các yêu cầu, các cách tiếp cận cũng như các thách thức mà phân cụm dữ liệu và luật kết hợp đang gặp phải, đi sâu tìm hiểu thuật toán K_means và thuật toán Apriori.
Chương 3: Ứng dụng khai phá dữ liệu xây dựng hệ thống trợ giúp phòng, chống và giảm nhẹ rủi ro thiên tai tại trường học
Chương này trình bày lý do chọn bài toán, các cơ sở giải quyết bài toán (lý luận, thực tiễn, khoa học…). Cài đặt chương trình thử nghiệm ứng dụng kỹ thuật phân cụm và luật kết hợp và một số kết quả thu được.

CHƯƠNG 1
TỔNG QUAN VỀ PHÁT HIỆN TRI THỨC
VÀ KHAI PHÁ DỮ LIỆU
1.1. KHÁM PHÁ TRI THỨC VÀ KHAI PHÁ DỮ LIỆU
“Khám phá tri thức là quá trình tìm ra những tri thức, đó là những mẫu tìm ẩn, trước đó chưa biết và là thông tin hữu ích đáng tin cậy”. Còn khai phá dữ liệu là một bước quan trọng trong quá trình khám phá tri thức, sử dụng các thuật toán khai phá dữ liệu chuyên dùng với một số quy định về hiệu quả tính toán chấp nhận được để chiết xuất ra các mẫu hoặc các mô hình có ích trong dữ liệu. Nói một cách khác, mục đích của khám phá tri thức và khai phá dữ liệu chính là tìm ra các mẫu hoặc mô hình đang tồn tại trong các CSDL nhưng vẫn còn bị che khuất bởi hàng núi dữ liệu [1].
1.2. QUÁ TRÌNH KHÁM PHÁ TRI THỨC
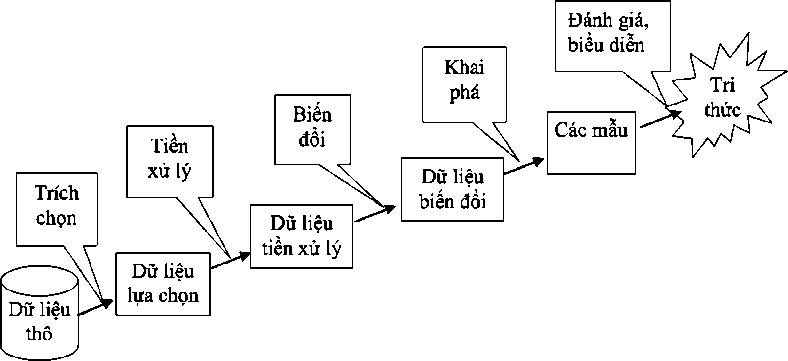
Hình 1.1. Quá trình khám phá tri thức [11]
Quá trình khám phá tri thức từ CSDL là một quá trình có sử dụng nhiều phương pháp và công cụ tin học nhưng vẫn là một quá trình mà trong đó con người là trung tâm. Do đó, nó không phải là một hệ thống phân tích tự động mà là một hệ thống bao gồm nhiều hoạt động tương tác thường xuyên giữa con người và CSDL, tất nhiên là với sự hỗ trợ của các công cụ tin học.
1.2.1. Gom dữ liệu (Gathering)
1.2.2. Trích lọc dữ liệu (Selection)
1.2.3 Làm sạch, tiền xử lý và chuẩn bị trước dữ liệu (Cleansing, Pre-processing and Preparation)
1.2.4. Chuyển đổi dữ liệu (Transformation)
1.2.5. Khai phá dữ liệu (Data Mining)
1.2.6. Đánh giá kết quả mẫu (Evaluation of Result)
1.3. CÁC LOẠI DỮ LIỆU CÓ THỂ KHAI PHÁ
Các loại dữ liệu có thể được khai phá như sau:
– CSDL quan hệ (relational databases)
– CSDL đa chiều (multidimention structures, data warehouse, data mart)
– CSDL giao tác (transaction databases)
– CSDL quan hệ – hướng đối tượng (object relational databases)
– CSDL không gian và thời gian (spatial, temporal, and time – series data)
– CSDL đa phương tiện (Multimedia database)
1.4. CÁC PHƯƠNG PHÁP, KỸ THUẬT CHÍNH TRONG KHAI PHÁ DỮ LIỆU
Các kỹ thuật khai phá dữ liệu được có thể chia làm 2 nhóm chính [5]:
– Kỹ thuật khai phá dữ liệu mô tả
– Kỹ thuật khai phá dữ liệu dự đoán:
1.4.1. Phân lớp và dự đoán (Classification & Prediction)
1.4.2. Luật kết hợp (Association Rules)
1.4.3. Khai thác mẫu tuần tự (Sequential / Temporal patterns)
1.4.4. Phân nhóm- đoạn (Clustering / Segmentation)
1.4.5. Hồi quy (Regression)
1.4.6. Tổng hợp hóa (Summarization)
1.4.7. Mô hình hóa sự phụ thuộc (dependency modeling)
1.4.8. Phát hiện sự biến đổi và độ lệch (Change and deviation detection)
1.5. NHỮNG KHÓ KHĂN TRONG KHAI PHÁ DỮ LIỆU
Khám phá tri thức và khai phá dữ liệu liên quan đến nhiều ngành, nhiều lĩnh vực trong thực tế, vì vậy các thách thức và khó khăn ngày càng nhiều, càng lớn hơn. Sau đây là một số các thách thức và khó khăn cần được quan tâm [5]:
– Các CSDL lớn hơn rất nhiều
– Số chiều cao
– Thay đổi dữ liệu và tri thức
– Dữ liệu thiếu và bị nhiễu
– Mối quan hệ phức tạp giữa các trường
– Tính dễ hiểu của các mẫu
– Người dùng tương tác và tri thức sẵn có
– Tích hợp với các hệ thống khác
1.6. ỨNG DỤNG CỦA KHAI PHÁ DỮ LIỆU
Khai phá dữ liệu có nhiều ứng dụng trong thực tế, một số ứng dụng điển hình như [6]:
Bảo hiểm, tài chính và thị trường chứng khoán
Điều trị y học và chăm sóc y tế
Sản xuất và chế biến
Text mining & Web mining
Lĩnh vực khoa học
Lĩnh vực khác
1.7. KẾT LUẬN
Khai phá dữ liệu là lĩnh vực đã và đang trở thành một trong những hướng nghiên cứu thu hút được sự quan tâm của nhiều chuyên gia về công nghệ thông tin trên thế giới. Điều này chứng tỏ những ưu thế, lợi ích và khả năng ứng dụng thực tế to lớn của khai phá dữ liệu. Chương này đã trình bày một số kiến thức tổng quan về khám phá tri thức, những khái niệm và kiến thức cơ bản nhất về khai phá dữ liệu.
TÌM HIỂU PHÂN CỤM DỮ LIỆU, LUẬT KẾT HỢP, THUẬT TOÁN K_MEANS VÀ THUẬT TOÁN APRIORI
2.1. KHÁI NIỆM VÀ MỤC TIÊU CỦA PHÂN CỤM DỮ LIỆU
2.1.1. Khái niệm phân cụm dữ liệu
Phân cụm dữ liệu là một kỹ thuật trong Data mining nhằm tìm kiếm, phát hiện các cụm, các mẫu dữ liệu tự nhiên tiềm ẩn và quan trọng trong tập dữ liệu lớn để từ đó cung cấp thông tin, tri thức cho việc ra quyết định.
Phân cụm dữ liệu là sự phân chia một CSDL lớn thành các nhóm dữ liệu với trong đó các đối tượng tương tự như nhau. Trong mỗi nhóm, một số chi tiết có thể không quan tâm đến để đổi lấy dữ liệu đơn giản hóa. Hay ta có thể hiểu “Phân cụm dữ liệu là quá trình tổ chức các đối tượng thành từng nhóm mà các đối tượng ở mỗi nhóm đều tương tự nhau theo một tính chất nào đó, những đối tượng không tương tự tính chất sẽ ở nhóm khác” [1].
Như vậy, phân cụm dữ liệu là quá trình phân chia một tập dữ liệu ban đầu thành các cụm dữ liệu sao cho các đối tượng trong một cụm “tương tự” (Similar) với nhau và các đối tượng trong các cụm khác nhau sẽ “không tương tự” (Dissimilar) với nhau. Số các cụm dữ liệu được phân ở đây có thể được xác định trước theo kinh nghiệm hoặc có thể được tự động xác định.
 Chúng ta có thể thấy điều này với một ví dụ đơn giản như sau [13]:
Chúng ta có thể thấy điều này với một ví dụ đơn giản như sau [13]:
Hình 2.1: Ví dụ về phân cụm dữ liệu
Trong trường hợp này, chúng ta dễ dàng xác định được 4 cụm dựa vào các dữ liệu đã cho; các tiêu chí “tương tự” để phân cụm trong trường hợp này là khoảng cách: hai hoặc nhiều đối tượng thuộc nhóm của chúng được “đóng gói” theo một khoảng cách nhất định. Điều này được gọi là phân cụm dựa trên khoảng cách.
Một kiểu khác của phân cụm dữ liệu là phân cụm dữ liệu dựa vào khái niệm: hai hay nhiều đối tượng thuộc cùng nhóm nếu có một định nghĩa khái niệm chung cho tất cả các đối tượng trong đó. Nói cách khác, đối tượng của nhóm phải phù hợp với nhau theo miêu tả các khái niệm đã được định nghĩa, không phải theo những biện pháp đơn giản tương tự.
2.1.2. Các mục tiêu của phân cụm dữ liệu
Mục tiêu của phân cụm dữ liệu là để xác định các nhóm nội tại bên trong một bộ dữ liệu không có nhãn. Nhưng để có thể quyết định được cái gì tạo thành một cụm tốt. Nhưng làm thế nào để quyết định cái gì đã tạo nên một phân cụm dữ liệu tốt? Nó có thể được hiển thị rằng không có tiêu chuẩn tuyệt đối “tốt nhất” mà sẽ là độc lập với mục đích cuối cùng của phân cụm dữ liệu. Do đó, mà người sử dụng phải cung cấp tiêu chuẩn, theo cách như vậy mà kết quả của phân cụm dữ liệu sẽ phù hợp với nhu cầu của họ cần.
2.2. CÁC ỨNG DỤNG CỦA PHÂN CỤM DỮ LIỆU
Phân cụm dữ liệu có thể ứng dụng trong nhiều lĩnh vực như [12]:
– Thương mại: tìm kiếm nhóm các khách hàng quan trọng dựa vào các thuộc tính đặc trưng tương đồng và những đặc tả của họ trong các bản ghi mua bán của CSDL;
– Sinh học: phân loại động, thực vật qua các chức năng gen tương đồng của chúng;
– Thư viện: phân loại các cụm sách có nội dung và ý nghĩa tương đồng nhau để cung cấp cho độc giả, cũng như đặt hàng với nhà cung cấp;
– Bảo hiểm: nhận dạng nhóm tham gia bảo hiểm có chi phí yêu cầu bồi thường trung bình cao, xác định gian lận trong bảo hiểm thông qua các mẫu cá biệt;
– Quy hoạch đô thị: nhận dạng các nhóm nhà theo kiểu, vị trí địa lí, giá trị … nhằm cung cấp thông tin cho quy hoạch đô thị;
– Nghiên cứu địa chấn: phân cụm để theo dõi các tâm động đất nhằm cung cấp thông tin cho việc nhận dạng các vùng nguy hiểm;
– WWW: tài liệu phân loại, phân nhóm dữ liệu weblog để khám phá các nhóm về các hình thức tiếp cận tương tự trợ giúp cho việc khai phá thông tin từ dữ liệu.
2.3. CÁC YÊU CẦU VÀ NHỮNG VẤN ĐỀ CÒN TỒN TẠI TRONG PHÂN CỤM DỮ LIỆU
2.3.1. Các yêu cầu của phân cụm dữ liệu
Phân cụm là một thách thức trong lĩnh vực nghiên cứu ở chỗ những ứng dụng tiềm năng của chúng được đưa ra ngay chính trong những yêu cầu đặc biệt của chúng. Sau đây là những yêu cầu cơ bản của phân cụm trong khai phá dữ liệu:
– Có khả năng mở rộng
– Khả năng thích nghi với các kiểu thuộc tính khác nhau
– Khám phá các cụm với hình dạng bất kỳ
– Tối thiểu lượng tri thức cần cho xác định các tham số đầu vào
– Khả năng thích nghi với dữ liệu nhiễu
– Ít nhạy cảm với thứ tự của các dữ liệu vào
– Số chiều lớn
– Phân cụm ràng buộc
– Dễ hiểu và dễ sử dụng
Với những yêu cầu đáng lưu ý này, nghiên cứu của ta về phân tích phân cụm diễn ra như sau:
Đầu tiên, ta nghiên cứu các kiểu dữ liệu khác nhau và cách chúng có thể gây ảnh hưởng tới các phương pháp phân cụm.
Thứ hai, ta đưa ra một cách phân loại chung trong các phương pháp phân cụm.
Sau đó, ta nghiên cứu chi tiết mỗi phương pháp phân cụm, bao gồm các phương pháp phân hoạch, phân cấp, dựa trên mật độ… Ta cũng khảo sát sự phân cụm trong không gian đa chiều và các biến thể của các phương pháp khác.
2.3.2. Những vấn đề còn tồn tại trong phân cụm dữ liệu
Có một số vấn đề với phân cụm dữ liệu. Một trong số đó là [12]:
– Kỹ thuật clustering hiện nay không trình bày được tất cả các yêu cầu đầy đủ (và đồng thời);
– Giao dịch với số lượng lớn các mẫu và số lượng lớn các mẫu tin của dữ liệu có thể gặp vấn đề phức tạp về thời gian;
– Hiệu quả của phương pháp phụ thuộc vào định nghĩa của “khoảng cách” (đối với phân cụm dữ liệu dựa trên khoảng cách). Nếu không tồn tại một thước đo khoảng cách rõ ràng chúng ta “phải tự xác định”, một điều mà không thật sự dễ dàng chút nào, nhất là trong không gian đa chiều;
– Kết quả của thuật toán phân cụm dữ liệu có thể được giải thích theo nhiều cách khác nhau (mà trong nhiều trường hợp chỉ có thể được giải thích theo ý riêng của mỗi người).
2.4. THUẬT TOÁN K_MEANS
Thuật toán K_means được mô tả như sau:
– D là tập dữ liệu cần phân hoạch
– Số lượng cụm k, với k là số nguyên
Output:
– Danh sách k nhóm: C1, C2, . . ., Ck
Begin
For i:=1 to k
Begin
Chọn ngẫu nhiên ri D làm trọng tâm của Ci
End;
While có thay đổi trong các nhóm Ci
Begin
For mỗi x D
Begin
Tính d(x, ri), i=1. . .k
Đưa x vào nhóm Cj nếu d(x, rj) <= d(x, ri),
i j, i=1 . . .k
End;
For i:=1 to k
Begin
Tính lại các trọng tâm ri
End;
End;
End.
2.5. LUẬT KẾT HỢP TRONG KHAI PHÁ DỮ LIỆU (ASSOCIATION RULE IN DATA MINING)
Trong lĩnh vực khai phá dữ liệu, mục đích của luật kết hợp (Association Rule – AR) là tìm ra các mối quan hệ giữa các đối tượng trong khối lượng lớn dữ liệu. Nội dung cơ bản của luật kết hợp được tóm tắt như dưới đây.
Cho cơ sở dữ liệu gồm các giao dịch T là tập các giao dịch t1, t2, …, tn.
T = {t1, t2, …, tn}. T gọi là cơ sở dữ liệu giao dịch (Transaction Database)
Mỗi giao dịch ti bao gồm tập các đối tượng I (gọi là itemset)
I = {i1, i2, …, im}. Một itemset gồm k items gọi là k-itemset
Mục đích của luật kết hợp là tìm ra sự kết hợp (association) hay tương quan (correlation) giữa các items. Những luật kết hợp này có dạng X 🡪Y
2.6. THUẬT TOÁN SINH CÁC LUẬT KẾT HỢP APRIORI (by Agrawal and Srikant 1994)
Tư tưởng chính của thuật toán Apriori là:
– Tìm tất cả frequent itemsets:
k-itemset (itemsets gồm k items) được dùng để tìm (k+1)- itemset.
Đầu tiên tìm 1-itemset (ký hiệu L1). L1 được dùng để tìm L2 (2-itemsets). L2 được dùng để tìm L3 (3-itemset) và tiếp tục cho đến khi không có k-itemset được tìm thấy.
– Từ frequent itemsets sinh ra các luật kết hợp mạnh (các luật kết hợp thỏa mãn 2 tham số min_sup và min_conf)
Thuật toán Apriori được mô tả như sau:
| Input: – Tập các giao dịch D, ngưỡng support tối thiểu minsup |
| Output: – L- tập mục phổ biến trong D |
| L1=Large_1_ItemSets() |
| for (k=2; Lk-1 ≠ ∅; k++) do |
| Begin |
| Ck=apriori-gen(Lk-1); |
| for (mỗi một giao dịch TD) do |
| Begin |
| CT = subset(Ck, T); |
| for (mỗi một ứng cử viên c CT) do |
| c.count++; |
| End; |
| Lk = {c ∈ Ck| c.count ≥ minsup} |
| End; |
| return ∪kLk |
- Hàm Large_1_ItemSets() trả về các Item có số support lớn hơn hay bằng minsup.
| for all transaction t ∈ D do |
| for all item i ∈ t do |
| i.count ++; |
| L1={i | i.count ≥ minsup}; |
- Hàm apriori_gen (Lk-1) thực hiện việc kết các cặp (k-1) ItemSet để phát sinh các tập k_ItemSet mới. Tham số của hàm là Lk-1 – tập tất cả các (k-1)-ItemSet và kết quả trả về của hàm là tập các k-ItemSet.
| Join Lk-1 with Lk-1; |
| Insert into Ck |
| select p.item1,p.item2, . . .p.itemk-1, q.itemk-1 |
| from Lk-1 as p, Lk-1 as q; |
| where (p.item1= q.item1)∧…∧(p.itemk-2 = q.item k-2)∧(p.item k-1<q.item k-1); Điều kiện (p.item k-1<q.item k-1) sẽ bảo đảm không phát sinh các bộ trùng nhau. |
2.7. KẾT LUẬN
Phân cụm dữ liệu là qui trình tìm cách nhóm các đối tượng đã cho vào các cụm (clusters), sao cho các đối tượng trong cùng 1 cụm càng giống nhau càng tốt và các đối tượng khác cụm thì càng kacs nhau càng tốt.
Mục đích của phân cụm là tìm ra bản chất bên trong các nhóm của dữ liệu. Có rất nhiều kỹ thuật phân cụm như phân cụm phân hoạch, phân cụm phân cấp, phân dựa trên mật độ…Tuy nhiên không có tiêu chí nào được xem là tốt nhất để đánh giá hiệu quả của phân tích phân cụm, điều này phụ thuộc vào mục đích của bài toán phân cụm.
ỨNG DỤNG KHAI PHÁ DỮ LIỆU XÂY DỰNG HỆ THỐNG TRỢ GIÚP PHÒNG, CHỐNG VÀ GIẢM NHẸ RỦI RO
THIÊN TAI TẠI TRƯỜNG HỌC
3.1. ĐẶT VẤN ĐỀ
Việt Nam là một trong những quốc gia thường xuyên chịu tác động bởi thiên tai. Trong đó phổ biến và nghiêm trọng nhất là bão, lũ, lụt, sạt lở đất giông sét,…Thiên tai đã tàn phá rất nhiều công trình, gây ra nhiều thiệt hại về tính mạng, tài sản của cộng đồng và xã hội. Trong đó, các cơ sở giáo dục như trường học, các trung tâm giáo dục thường xuyên,…phải hứng chịu những tổn thất nặng nề.
Để nâng cao năng lực phòng ngừa và ứng phó thiên tai cho giáo viên và học sinh, nhiều nước đã xây dựng mô hình trường học an toàn trong hoạt động phòng, chống thiên tai như Myanmar, Indonesia, Sri Lanka, Bangladesh, Ấn độ, Nhật Bản, Mỹ,…Việc đầu tư phòng chống thiên tai đã được ngân hàng thế giới chứng minh là sẽ giảm được rất nhiều chi phí để khắc phục hậu quả sau này, do cứ 1 đô la đầu tư vào giảm nhẹ rủi ro thiên tai sẽ giúp tiết kiệm được 7 đô la dùng cho công tác phục hồi.
3.2. CƠ SỞ LÝ LUẬN VÀ KHOA HỌC THỰC TIỄN
3.2.1. Cơ sở lý luận
Trong những năm qua, Chính phủ Việt Nam đã có nhiều chủ trương, chính sách nhằm nâng cao năng lực phòng, tránh thiên tai và thích ứng biến đổi khí hậu, cụ thể là Chiến lước quốc gia phòng, chống và giảm nhẹ thiên tai đến 2020 và Chiến lược quốc gia về biến đổi khí hậu [2].
Đề án nâng cao nhận thức cộng đồng và quản lý rủi ro thiên tai dựa vào cộng đồng được Thủ tướng phê duyệt tại Quyết định số 1002/QĐ-TTg ngày 13/07/2009 với mục tiêu đến năm 2020, 100% cán bộ chính quyền các cấp trực tiếp làm công tác phòng, chống thiên tai được đào tạo tập huấn, nâng cao năng lực và 70% người dân các xã thuộc vùng thường xuyên chịu ảnh hưởng bởi thiên tai được tăng cường nhận thức, kỹ năng trong giảm nhẹ thiên tai, qua đó người dân chủ động tham gia đánh giá hiểm họa, xác định nguồn lực, xây dựng kế hoạch phòng, chống thiên tai.
3.2.2. Cơ sở thực tiễn
Thiên tai ảnh hưởng nghiêm trọng đến các hoạt động của một cộng đồng dân cư hoặc một xã hội, gây ra những tác hại hoặc mất mát về tính mạng, tài sản, kinh tế hoặc môi trường, do các hiểm họa tự nhiên gây ra và vượt ngoài khả năng tự đối phó của cộng đồng hay xã hội đó.
Trong thời gian qua các cơ sở giáo dục đã từng bước giảng dạy lồng ghép các môn học như Địa lí, Sinh học, Giáo dục công dân… với phòng, chống giảm nhẹ rủi ro thiên tai, biến đổi khí hậu và các rủi ro khác, tổ chức ngoại khóa tìm hiểu, dự đoán tình huống, tập huấn kỹ năng khi có rủi ro thiên tai xảy ra nhằm giảm thiểu thiệt hại về người và tài sản.
3.2.3. Cơ sở khoa học
Khi thiên tai xảy ra, thiệt hại tại một địa phương có thể lớn hoặc nhỏ và phụ thuộc vào nhiều yếu tố như: Đặc điểm thiên tai xảy ra, tình trạng dễ bị tổn thương và năng lực phòng, chống thiên tai.
Rủi ro thiên tai (mức độ thiệt hại có thể xảy ra) sẽ tăng lên nếu thiên tai tác động đến một cộng đồng có nhiều yếu tố dễ bị tổn thương và có năng lực phòng, chống thiên tai hạn chế.
Và ngược lại, rủi ro thiên tai sẽ giảm nếu cộng đồng đó có năng lực phòng, chống thiên tai tốt hơn.
Mối quan hệ giữa rủi ro thiên tai, tình trạng dễ bị tổn thương và năng lực phòng, chống thiên tai được thể hiện qua biểu thức sau:
| Rủi ro thiên tai ⬄ | Cấp độ thiên tai & Tình trạng dễ bị tổn thương |
| Năng lực phòng, chống thiên tai |
Chương này tập trung nghiên cứu kỹ thuật phân cụm và luật kết hợp cài đặt chương trình bằng 2 thuật toán chính đó là thuật toán K_means và thuật toán Apriori.
3.3. BIỂU MẪU BAN ĐẦU [4][3].
3.3.1. Biểu xác định các loại thiên tai
| TT | Thiên tai | Có | Không | Thời gian hay xảy ra |
| 1 | Bão | |||
| 2 | Lũ | |||
| 3 | Lụt | |||
| 4 | Lũ quét | |||
| 5 | Sạt lở đất |
3.3.2. Cơ sở vật chất giúp nhà trường an toàn trước thiên tai
| TT | Nội dung | Có | Không | Ghi chú |
| Vị trí địa lí của trường học | ||||
| 1 | Trường học có vị trí chống chịu tốt khi thiên tai xảy ra (Ví dụ: ở trên khu vực cao, nền đất vững chắc, không hoặc ít ngập,…) | |||
| 2 | Trường học ở gấn vị trí trục đường giao thông chính | |||
| 3 | Trường học có vị trí cách xa các địa điểm dễ gây nguy hiểm như đê, biển, sông, hồ lớn, nhà máy công nghiệp, khu chứa vật liệu dễ cháy nổ,… từ 1km trở lên | |||
| Kết cấu của trường học | ||||
| 1 | Trường học được xây dựng theo các quy chuẩn, tiêu chuẩn quốc gia, có khả năng chịu thiên tai thường xảy ra tại khu vực | |||
| 2 | Trường học có mái vững chắc (ví dụ: mái ngói hoặc mái bê tông cốt thép,…) | |||
| 3 | Trường học có lối thoát hiểm đủ rộng (kể cả cho người khuyết tật) để sơ tán trong trường hợp khẩn cấp | |||
| Dụng cụ | ||||
| 1 | Có trang thiết bị phòng, chữa cháy(bình cứu hỏa, thang, bao cát, xô đựng nước) đặt ở nơi thuận tiện cho việc sử dụng, được kiểm tra thường xuyên, còn hạn sử dụng và không có chướng ngại vật xung quanh bình cứu hỏa | |||
| 2 | Có dụng cụ báo động sử dụng được ngay cả khi không có điện trongtrường hợp khẩn cấp (ví dụ trống, còi, loa chạy pin,…) | |||
| 3 | Có bộ sơ cứu và các loại thuốc cơ bản | |||
| Các dụng cụ trang thiết bị khác (phù hợp với vùng địa lí và loại thiên tai thường xảy ra) | ||||
| 1 | Áo phao, phao | |||
| 2 | Thuyền | |||
| 3 | Có dụng cụ di chuyển người khuyết tật như cáng, xe lăn | |||
3.3.3. Quản lí trường học an toàn
| TTT | Nội dung | Có | Không | Ghi chú |
| Quản lí an toàn trường học | ||||
| 1 | Ban quản lí thiên tai của trường học (BQL) được thành lập (bao gồm giáo viên, phụ huynh học sinh, thành viên Hội chữ thập đỏ, thành viên ban PC&GNTT,…) | |||
| 2 | Trường học có bảng phân công nhiệm vụ cụ thể cho từng thành viên BQL | |||
| 3 | Trường học có đầy đủ thông tin liên hệ của gia đình học sinh trong trường hợp khẩn cấp | |||
3.3.4. Giáo dục về phòng chống và giảm nhẹ thiên tai trong trường học
| TT | Nội dung | Có | Không | Ghi chú |
| 1 | BQL có kiến thức về thiên tai và cách phòng, chống | |||
| 2 | Cán bộ BQL biết cách thực hiện kế hoạch | |||
| 3 | Giáo viên biết cách sơ cấp cứu |
3.3.5. Các thông tin về khu vực xung quanh trường học
| TT | Nội dung | Có | Không | Ghi chú |
| 1 | Sông, suối, ao hồ, kênh rạch | |||
| 2 | Khu vực sạt lở ven sông, ven biển | |||
| 3 | Khu vực xảy ra sạt lở đất từ đồi/núi |
3.3.6. Các mối nguy hiểm trên đường đến trường
| TT | Nội dung | Có | Không | Ghi chú |
| 1 | Học sinh có vượt đường núi đến trường | |||
| 2 | Có đường điện cao thế, hạ thế gần trường học | |||
| 3 | Trên đường đến trường có cây to, đất đá, cầu không vững hay các thứ khác dễ rơi bất ngờ khi có thiên tai xảy ra |
3.4. CẤU TRÚC DỮ LIỆU CỦA CHƯƠNG TRÌNH
Dữ liệu được sử dụng trong chương trình này là nguồn dữ liệu mẫu để thử nghiệm chương trình Demo, dữ liệu đã được chỉnh sửa phù hợp với yêu cầu khai thác dữ liệu.
Bộ dữ liệu bao gồm:
3.4.1. Tập tin dữ liệu danh sách trường
Tập tin dữ liệu này phản ánh toàn bộ các thông tin phát sinh về thiên tai hàng năm ảnh hưởng đến nhà trường như thế nào.
| ID | loai | thoi gian | quan ly | giao duc | gia tri | vi tri | moi nguy hiem | dung cu | thien tai |
| ID12101 | 1 | 1 | 1 | 1 | 79 | 0 | 1 | 0 | 1 |
| ID12102 | 2 | 1 | 1 | 1 | 93 | 0 | 3 | 0 | 1 |
| ID12103 | 0 | 3 | 1 | 0 | 36 | 0 | 0 | 0 | 0 |
| ID12104 | 1 | 2 | 0 | 0 | 45 | 0 | 3 | 1 | 2 |
| ID12105 | 2 | 3 | 0 | 0 | 42 | 1 | 0 | 0 | 1 |
| ID12106 | 2 | 3 | 0 | 1 | 47 | 0 | 2 | 0 | 2 |
| ID12107 | 0 | 3 | 1 | 1 | 78 | 1 | 0 | 0 | 2 |
| … |
3.4.2. Thông tin chi tiết các trường
Dựa vào dữ liệu thu thập trong phiếu điều tra để chuyển đổi dữ liệu từ dạng không có cấu trúc sang cấu trúc như hình bên trên. Trong quá trình sử dụng tập tin dữ liệu này để khai thác luật kết hợp và phân cụm dữ liệu thì chương trình chỉ sử dụng các thuộc tính được giải thích trong bảng sau:
| Tên trường | Giải thích |
| Loai() | 0: Tiểu học 1: Trung học cơ sở 2: Trung học phổ thông |
| Giatri() | 0: “Trường học có vị trí chống chịu tốt khi thiên tai xẩy ra”; 1: “Trường học có vị trí cách xa các địa điểm dễ gây nguy hiểm như đê, biển, sông, hồ lớn, nhà máy công nghiệp, khu chứa vật liệu dễ cháy nổ,… từ 1km trở lên”; . . . |
| Vitri() | 0: “Trường học có vị trí chống chịu tốt khi thiên tai xẩy ra”; 1: “Trường học có vị trí cách xa các địa điểm dễ gây nguy hiểm như đê, biển, sông, hồ lớn, nhà máy công nghiệp, khu chứa vật liệu dễ cháy nổ,… từ 1km trở lên”; . . . |
| Moinguyhiem() | 0: “Có đường điện cao thế, hạ thế gần trường học”; 1: “Học sinh có vượt đường núi đến trường”; 2: “Học sinh có đi đò, lội qua suối hay đường bị ngập lụt để đến trường”; 3: “Trên đường đến trường có thung lũng hoặc dốc núi, sườn đồi/núi dễ sạt lở”; . . . |
| Thientai() | 0: “Mưa bão”; 1: “Hạn hán, hỏa hạn”; 2: “Động đất, sóng thần”; . . . |
Cơ sở dữ liệu thông tin về thiên tai sẽ được sử dụng để khai thác luật kết hợp và phân cụm dự đoán các rủi ro thiên tai nhằm:
Giúp các cấp lãnh đạo quản lý, báo cáo, lập kế hoạch phòng chống và giảm nhẹ rủi ro thiên tai trước, trong và sau khi thiên tai xảy ra một cách chủ động, tích cực, kịp thời và hiệu quả.
3.5. GIẢI PHÁP THỰC HIỆN
3.5.1. Mô tả hệ thống
Mục đích: Ứng dụng kỹ thuật phân cụm và luật kết hợp phân tích dữ liệu trường học có thể gặp rủi ro khi có thiên tai xảy ra.
Đầu vào: Thu thập các thông tin về trường học, cơ sở vật chất, vị trí địa lí của trường, vị trí địa lí khu vực gần trường, những nguy cơ rủi ro trên đường tới trường, thông tin về học sinh, cán bộ, giáo viên, nhân viên.
Đầu ra: Dự báo mức độ nguy cơ rủi ro khi có thiên tai xảy ra ở các trường, nhóm các trường có khả năng chống chịu thiên tai gần giống nhau.
3.5.2. Kịch bản triển khai và phân tích dữ liệu
Hệ thống phân tích dữ liệu tiến hành theo các bước
B1: Thu thập và tiền xử lý dữ liệu
B2: Xây dựng mô hình phân cụm và luật kết hợp
B3: Phát hiện tri thức từ mô hình dự đoán
B4: Ứng dụng tri thức phát hiện vào dự đoán rủi ro thiên tai tại trường học
Bước 1: Thu thập và tiền xử lý dữ liệu
Dữ liệu thu thập 200 mẫu, dữ liệu ban đầu gồm rất nhiều thuộc tính, sau quá trình tiền xử lý dữ liệu (sử dụng phương pháp trích chọn thuộc tính) để đánh giá mức độ ảnh hưởng của thiên tai đến các thuộc tính.
Bước 2: Xây dựng mô hình phân cụm và luật kết hợp
Phân cụm giá trị (khả năng chống chịu) của trường học khi thiên tai xảy ra, khai phá luật kết hợp dựa vào thiên tai và các thuộc tính vị trí trường học, dụng cụ trang thiết bị, thông tin khu vực xung quanh trường học, các mối nguy hiểm…để xác định các rủi ro có thể gặp phải là bao nhiêu %.
Bước 3: Phát hiện tri thức từ mô hình phân cụm và luật kết hợp
Mô hình phân cụm

Hình 3.1. Giao diện phân cụm dữ liệu điểm đánh giá
phòng chống thiên tai.
Từ mô hình phân cụm, ví dụ chọn 3 cụm ta có cụm 1 tâm cụm là 85.5, số phần tử là 193, chiếm tỷ lệ 32.1%, cụm 2 tâm cụm là 19.1, số phần tử là 206, chiếm tỷ lệ 34.3%, cụm 3 tâm cụm là 52.1, số phần tử là 201, chiếm tỷ lệ 33.5%. Dựa vào đây các cấp lãnh đạo có thể chọn ra những trường có khả năng chống chịu thiên tai thấp để đầu tư xây dựng một số hạng mục góp phần giảm thiểu rủi ro khi thiên tai xảy ra.
Mô hình luật kết hợp

Hình 3.2. Giao diện khai thác luật kết hợp từ thông tin phòng chống thiên tai.
Từ mô hình luật kết hợp, phát hiện tri thức về mối quan hệ giữa các thuộc tính liên quan đến thiên tai. Ví dụ luật được trích ra từ mô hình có ý nghĩa như sau:
Mưa, bão xảy ra thì khả năng các trường có đường điện cao thế, hạ thế gần trường học gặp rủi ro là 36.7%
Mưa, bão xảy ra thì khả năng các trường có vị trí cách xa các địa điểm dễ gây nguy hiểm như đê, biển, sông hồ lớn, nhà máy công nghiệp từ 1km trở lên gặp rủi ro là 30.83%
Động đất xảy ra các trường có vị trí chống chịu tốt thì khả năng xảy ra rủi ro là 34.75%
3.6. CÀI ĐẶT CHƯƠNG TRÌNH
3.6.1 Cài đặt phần cứng
3.6.2 Cài đặt phần mềm
3.6.3. Các chức năng chính của chương trình
Khai thác luật kết hợp phiếu điều tra thông tin thiên tai
Chức năng này sử dụng phương pháp khai thác luật kết hợp với thuộc tính đã được xác định để có thể cung cấp các luật được quan tâm, tránh phát sinh những luật không có ý nghĩa với người sử dụng.
Người dùng chọn loại trường khai thác luật kết hợp; nhập độ hỗ trợ tối thiểu và nhấn nút thực hiện để nhận về các luật kết hợp được sinh ra sinh ra từ chương trình.
Khai thác phân cụm dữ liệu thông tin đánh giá điểm số về phòng chống thiên tai các trường
Chức năng này sử dụng phương pháp phân cụm dữ liệu với thuộc tính đã được xác định để có thể cung cấp thông tin về các nhóm trường với các mức điểm đánh giá để các nhà làm kế hoạch có chính sách và kế hoạch phòng chống thiên tai hiệu quả.

Hình 3.3. Giao diện chính của chương trình.
3.7. KẾT LUẬN
Dựa vào mô hình đã xây dựng, đề tài xây dựng được một ứng dụng có thể hỗ trợ việc ra quyết định của các nhà quản lý giáo dục, đưa ra được các chính sách cho từng nhóm trường, dự báo được những rủi ro có thể gặp phải khi một thiên tai nào đó xảy ra. Giúp các trường, các nhà quản lý có cơ sở báo cáo, lập kế hoạch phòng, chống và giảm nhẹ rủi ro thiên tai, có cơ sở đầu tư, sửa chữa cơ sở vật chất và trang thiết bị cần thiết. Tuy nhiên các thuộc tính phân tích còn thiếu, việc xác định giá trị chống chịu rủi ro thiên tai vẫn còn định tính, do đó độ tin cậy chưa cao.
KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN
Trong quá trình tìm hiểu và hoàn thành luận văn tốt nghiệp với đề tài “Ứng dụng khai phá dữ liệu xây dựng hệ thống trợ giúp phòng, chống và giảm nhẹ rủi ro thiên tai tại trường học”, dù đã đạt được một số kết quả nhất định về kiến thức, về thực tế (chương trình phân tích, đánh giá, dự đoán rủi ro thiên tai xảy ra tại trường học ở tỉnh Kon Tum), nhưng bản thân nhận thấy phân cụm và luật kết hợp trong khai phá dữ liệu vẫn là một lĩnh vực nghiên cứu còn quá rộng lớn và còn đầy triển vọng bao hàm nhiều phương pháp, kỹ thuật, nhiều hướng nghiên cứu, tiếp cận khác nhau.
Đề tài đã cố gắng tập trung tìm hiểu, nghiên cứu, trình bày được một số kỹ thuật về thuật toán phân cụm dữ liệu và luật kết hợp phổ biến, dựa trên các phương pháp đã có, cài đặt thử nghiệm thuật toán K-means và Apriori vào chương trình.
Với những gì mà luận văn đã thực hiện và đạt được, hướng phát triển sau này của luận văn như sau:
Về thực tiễn : sẽ phát triển thành bài toán cấp độ Sở áp dụng vào đánh giá và dự đoán rủi ro cho các trường với số dữ liệu lớn hơn, bao quát hơn, nhiều thuộc tính, đặc trưng hơn, triển khai phân quyền thu thập dữ liệu trực tuyến để có những đánh giá và xây dựng kế hoạch kịp thời…
Về lý thuyết : tiếp tục nghiên cứu tiếp cách phương pháp, các cách tiếp cận mới về phân cụm dữ liệu và luật kết hợp như : phân cụm thống kê, phân cụm khái niệm, phân cụm mờ…tìm kiếm, so sánh và chọn lựa thuật toán tối ưu nhất để giải quyết bài toán đã đưa ra, đồng thới tiến hành phát triển đề tài dựa trên GIS để xây dựng nên các bản đồ thể hiện cụ thể rủi ro thiên tai ở từng cơ sở giáo dục.
Mặc dù đã cố gắng tập trung nghiên cứu và tham khảo nhiều tài liệu, bài báo, tạp chí khoa học trong và ngoài nước, nhưng do trình độ còn có nhiều giới hạn không thể tránh khỏi thiếu sót và hạn chế, rất mong được sự chỉ bảo đóng góp nhiều hơn nữa của các quý thầy cô giáo và các nhà khoa học.
E:\DỮ LIỆU COP CỦA CHỊ YẾN\DAI HOC DA NANG\HE THONG THONG TIN\LE VAN TRUNG



