

Phát triển mô hình truy vấn dữ liệu tùy chọn dựa trên ngữ nghĩa của câu truy vấn NL2SQL-SPARQL: Trường hợp câu truy vấn insert update
1. Tính cấp thiết của đề tài
Workflow hay tiến trình là một quá trình tự động hóa công việc, một phần hoặc toàn bộ. Trong quá trình đó, các tài liệu, thông tin hay các nhiệm vụ được truyền từ đối tượng tham gia này sang đối tượng khác để hành động tuân theo một tập hợp quy tắc nhất định.
Một vấn đề đặt ra trong nghiên cứu về tiến trình đó là sự cô lập dữ liệu cá nhân trong việc thực thi phân tán của một tiến trình trong đó bao gồm nhiều công cụ thực thi cục bộ, được gọi là máy thực thi. Nguyên tắc cô lập này không cho phép truy cập vào dữ liệu cá nhân của một máy thực thi của người khác. Lấy một ví dụ trong lĩnh vực y tế, khi xem xét một tiến trình điều trị bệnh tim mạch, tiến trình này có nhiều đối tượng tham gia như bệnh nhân, bác sĩ điều trị, bác sĩ phẩu thuật, trung tâm xét nghiệm, trung tâm chẩn đoán hình ảnh…Các đối tượng này có thể không tập trung tại một địa điểm, không chia sẻ cùng một hạ tầng thông tin và vì thế dữ liệu điều trị của họ có thể phân tán. Dữ liệu điều trị có thể nằm tại nhiều địa điểm khác nhau và cũng có thể dưới nhiều hình thức khác nhau, ví dụ như có có thể là một cơ sở dữ liệu MySQL, có thể là dữ liệu ngữ nghĩa RDF, hay tổ chức bằng MongoDB. Nhiều hình thức cơ sở dữ liệu sẽ gây khó khăn cho hệ thống của người dùng khi muốn truy vấn vào các kho dữ liệu mà họ cần tra cứu, chẳng hạn bác sĩ điều trị muốn truy vấn dữ liệu từ trung tâm xét nghiệm chẳng hạn.
Để giúp người dùng có thể truy vấn một cách dễ dàng với các mô hình cơ sở dữ liệu, mà phổ biến hiện nay là cơ sở dữ liệu ngữ nghĩa và cơ sở dữ liệu quan hệ, trong [5] các tác giả đã đề xuất mô hình truy vấn dữ liệu tùy chọn dựa trên ngữ nghĩa của câu truy vấn, mô hình này đề xuất giải pháp truy vấn cả hai mô hình CSDL là CSDL quan hệ và CSDL ngữ nghĩa chỉ với câu truy vấn bằng ngôn ngữ tự nhiên. Tuy nhiên bài báo [5] chỉ mới phát triển mô hình với bộ từ điển ngữ nghĩa giới hạn cho câu truy vấn SELECT, vì vậy để mở rộng khả năng ứng dụng của mô hình này trong thực tế, tôi đề xuất lựa chọn đề tài:
“Phát triển mô hình truy vấn dữ liệu tùy chọn dựa trên ngữ nghĩa của câu truy vấn NL2SQL-SPARQL: Trường hợp câu truy vấn insert update”
2. Mục tiêu
Mục tiêu chính của đề tài là phát triển và hoàn thiện mô hình NL2SQL – SPARQL để có thể thực thi các truy vấn đa dạng như INSERT, UPDATE, ..khi truy vấn bằng ngôn ngữ tự nhiên.
Để thoả mãn mục tiêu này thì cần đạt được những mục tiêu cụ thể sau:
– Nắm vững cách tổ chức & truy vấn của các mô hình cơ sở dữ liệu phổ biến.
– Nắm vững ngôn ngữ truy vấn SPARQL trong cơ sở dữ liệu ngữ nghĩa RDF.
– Nắm vững cách chuyển đổi từ câu truy vấn tự nhiên theo cấu trúc cho trước sang câu truy vấn của các mô hình cơ sở dữ liệu.
– Nền tảng có khả năng đưa ra những câu truy vấn đề nghị tương ứng với cấu trúc của loại cơ sở dữ liệu lựa chọn.
3. Đối tượng và phạm vi nghiên cứu
- Đối tượng nghiên cứu
- Cách tổ chức và cú pháp truy vấn dữ liệu của các mô hình cơ sở dữ liệu phổ biến như: Cơ sở dữ liệu ngữ nghĩa, cơ sở dữ liệu quan hệ.
- Cách chuyển đổi từ câu truy vấn bằng ngôn ngữ tự nhiên sang câu truy vấn ngữ nghĩa.
- Ngôn ngữ truy vấn SQL trong mô hình cơ sở dữ liệu quan hệ.
- Ngôn ngữ truy vấn SPARQL trong Web ngữ nghĩa.
3.2. Phạm vi nghiên cứu
Trong khuôn khổ của luận văn thuộc loại nghiên cứu, tôi chỉ giới hạn nghiên cứu các vấn đề sau:
- Giới hạn chuyển đổi các câu truy vấn INSERT và UPDATE từ SPARQL sang loại cơ sở dữ liệu lựa chọn
- Phương pháp lý thuyết
- Tiến hành thu thập và nghiên cứu các tài liệu có liên quan đến đề tài.
- Phương pháp thực nghiệm
- Thực hiện xây dựng hệ thống từ các kết quả nghiên cứu lý thuyết đáp ứng mục tiêu đặt ra.
– Kiểm tra, thử nghiệm, nhận xét và đánh giá kết quả.
5. Kết quả dự kiến
5.1. Lý thuyết
Hoàn thiện được mô hình NL2SQL-SPARQL để có thể thực thi các truy vấn đa dạng như INSERT, UPDATE …khi truy vấn bằng ngôn ngữ tự nhiên.
5.2. Thực tiễn
Mô hình thực nghiệm cho kết quả như dự kiến.
6. Bố cục luận văn
Luận văn dự kiến tổ chức thành 3 chương chính như sau:
Chương 1: TỔNG QUAN VỀ CÁC MÔ HÌNH CƠ SỞ DỮ LIỆU
CHƯƠNG 2: NGÔN NGỮ TRUY VẤN CƠ SỞ DỮ LIỆU QUAN HỆ VÀ CƠ SỞ DỮ LIỆU NGỮ NGHĨA
CHƯƠNG 3: PHÁT TRIỂN HỆ THỐNG TRUY VẤN DỮ LIỆU TÙY CHỌN DỰA TRÊN NGỮ NGHĨA CỦA CÂU TRUY VẤN

CHƯƠNG 1
TỔNG QUAN VỀ CÁC MÔ HÌNH CƠ SỞ DỮ LIỆU
Chương này trình bày tổng quan về: khái niệm của cơ sở dữ liệu và các mô hình cơ sở dữ liệu liên quan trực tiếp tới luận văn, tổ chức và cấu trúc câu truy vấn của cơ sở dữ liệu quan hệ SQL và cơ sở dữ liệu ngữ nghĩa SPARQL.
CƠ SỞ DỮ LIỆU LÀ GÌ?
Cơ sở dữ liệu (Database), viết tắt là CSDL hoặc DB, là một tập hợp các dữ liệu có quan hệ logic với nhau, có thể dễ dàng chia sẻ và được thiết kế nhằm đáp ứng các nhu cầu sử dụng của một tổ chức, cá nhân nào đó.
* Vai trò của CSDL?
Ngày nay, CSDL đã trở thành một phần không thể thiếu trong các hoạt động đời sống hàng ngày. Mỗi ngày, có thể bạn sử dụng nhiều CSDL khác nhau, nhiều lần khác nhau nhưng lại không nhận ra điều đó.
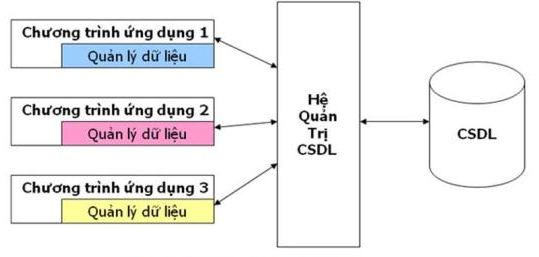
Hình 1.1. Vị trí của CSDL trong hệ thống
PHÂN LOẠI CÁC MÔ HÌNH CƠ SỞ DỮ LIỆU
Mô hình dữ liệu là một tập hợp tích hợp các khái niệm để mô tả và thao tác dữ liệu, mối quan hệ giữa các mô hình dữ liệu và các ràng buộc trên dữ liệu trong một tổ chức.
Cơ sở dữ liệu ngữ nghĩa
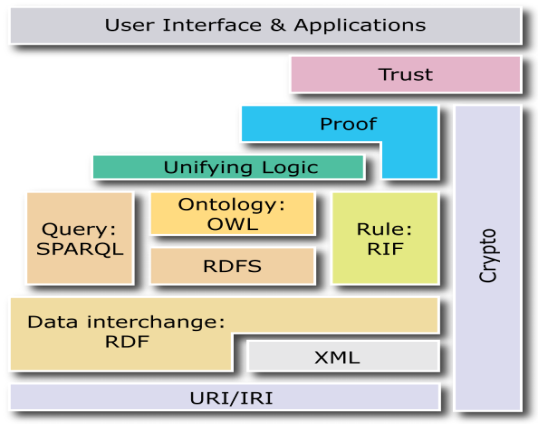 Tim Berners-Lee đã đề xuất một kiến trúc các lớp cho web ngữ nghĩa mà thường được biểu diễn bằng sơ đồ.
Tim Berners-Lee đã đề xuất một kiến trúc các lớp cho web ngữ nghĩa mà thường được biểu diễn bằng sơ đồ.
Hình 1.2: Kiến trúc các lớp của Web ngữ nghĩa
Hình 1.2 cho thấy các lớp của web ngữ nghĩa, trong đó mô tả các lớp chính của thiết kế Web ngữ nghĩa và tầm nhìn của nó.
Cơ sở dữ liệu quan hệ
Cơ sở dữ liệu quan hệ là một tập hợp các quan hệ được tiêu chuẩn hóa với những tên gọi quan hệ riêng biệt [15].
Các dạng chuẩn hóa cơ sở dữ liệu quan hệ
– Chuẩn hoá là quá trình tách bảng (phân rã) thành các bảng nhỏ hơn dựa vào các phụ thuộc hàm.
– Các dạng chuẩn là các chỉ dẫn để thiết kế các bảng trong CSDL.
– Mục đích của chuẩn hoá là loại bỏ các dư thừa dữ liệu và các lỗi khi thao tác dư thừa và các lỗi khi thao tác dữ liệu (Insert, Delete, Update).
– Nhưng chuẩn hoá làm tăng thời gian truy vấn.
Dạng chuẩn 1 – 1NF
Dạng chuẩn 2 – 2NF
Dạng chuẩn 3 – 3NF
Dạng chuẩn BCNF
Cơ sở dữ liệu hướng đối tượng
Dù có nhiều ngôn ngữ hướng đối tượng, đa số CSDL hướng đối tượng dựa trên C++. Lựa chọn này là do tính hiệu quả và thông dụng của C++.
CHƯƠNG 2
NGÔN NGỮ TRUY VẤN CƠ SỞ DỮ LIỆU QUAN HỆ VÀ CƠ SỞ DỮ LIỆU NGỮ NGHĨA
Chương này tìm hiểu kĩ hơn về tổ chức và cấu trúc câu truy vấn của cơ sở dữ liệu quan hệ SQL và cơ sở dữ liệu ngữ nghĩa SPARQL.
2.1 NGÔN NGỮ TRUY VẤN TRONG CƠ SỞ DỮ LIỆU QUAN HỆ
Ngôn ngữ truy vấn dữ liệu (Structured Query Language – SQL) cho phép những người khai thác CSDL (chuyên nghiệp hoặc không chuyên) sử dụng để truy vấn các thông tin cần thiết trong CSDL.
Ngôn ngữ quản lý dữ liệu (Data Control Language – DCL) cho phép những người quản trị hệ thống thay đổi cấu trúc của các bảng dữ liệu, khai báo bảo mật thông tin và cấp quyền hạn khai thác CSDL cho người sử dụng.
Tập hợp các câu lệnh truy vấn SQL được chia ra thành các nhóm với những mục đích như sau:
– Kiểm soát truy cập: GRANT, REVOKE
– Quản lý phiên làm việc: CONNECT, SET
– Định nghĩa dữ liệu: CREATE, ALTER, DROP
– Thao tác dữ liệu: UPDATE, SELECT, INSERT, DELETE
– Quản lý giao dịch: COMMIT, ROLLBACK, LOCK TABLE
– Câu lệnh nhập xuất
– Câu lệnh thủ tục: CALL
a. Câu lệnh SELECT
Cú pháp chung của câu lệnh SELECT có dạng: SELECT [ALL | DISTINCT][TOP n] danh_sách_ch ọn
[INTO tên_bảng_mới]
FROM danh_sách_bảng/khung_nhìn
[WHERE điều_kiện]
[GROUP BY danh_sách_cột]
[HAVING điều_kiện]
[ORDER BY cột_sắp_xếp]
[COMPUTE danh_sách_hàm_gộp [BY danh_sách_cột]]
b. Câu lệnh INSERT
Có hai dạng cú pháp cho lệnh INSERT INTO trong SQL như sau:
INSERT INTO TABLE_TEN (cot1, cot2, cot3,…cotN)]
VALUES (giatri1, giatri2, giatri3,…giatriN);
Ở đây, cot1, cot2,…cotN là tên các cột trong bảng mà bạn muốn chèn dữ liệu.
Bạn có thể không cần xác định tên các cột trong truy vấn SQL nếu bạn đang thêm các giá trị cho tất cả cột của bảng đó. Nhưng bạn nên đảm bảo thứ tự của các giá trị là giống như thứ tự các cột trong bảng. Cú pháp của lệnh INSERT INTO này như sau:
INSERT INTO TABLE_TEN VALUES (giatri1,giatri2,giatri3,…giatriN);
b. Câu lệnh UPDATE
Cú pháp cơ bản của truy vấn UPDATE với mệnh đề WHERE như sau:
UPDATE ten_bang
SET cot1 = giatri1, cot2 = giatri2…., cotN = giatriN
WHERE [dieu_kien];
c. Câu lệnh DELETE
Cú pháp của câu lệnh này như sau:
DELETE FROM tên_bảng
[FROM danh_sách_bảng]
[WHERE điều_kiện]
2.2. NGÔN NGỮ TRUY VẤN TRONG CƠ SỞ DỮ LIỆU NGỮ NGHĨA
Cơ sở dữ liệu ngữ nghĩa là ngôn ngữ và giao thức truy vấn tiêu chuẩn cho Dữ liệu Mở Liên kết trên web hoặc trong cơ sở dữ liệu đồ họa ngữ nghĩa (còn được gọi là RDF triplestore – bộ 3 RDF).
SPARQL, là viết tắt của Giao thức SPARQL và Ngôn ngữ Truy vấn RDF bằng tiếng Anh, “SPARQL Protocol And RDF Query Language”, cho phép những người sử dụng truy vấn thông tin từ các cơ sở dữ liệu hoặc bất kỳ nguồn dữ liệu nào có thể được ánh xạ tới RDF.
Cú pháp tổng quát của SPARQL-SELECT được liệt kê như sau:
PREFIX ns: <namespaceURI> PREFIX : <.>
SELECT variables [FROM <dataURI>]
[FROM NAMED <dataURI>]
WHERE { constraints [FILTER] [OPTIONAL] } [ORDER BY variables] [OFFSET/LIMIT n] [DISTINCT]
Dữ liệu trong RDF được mô tả theo dạng các bộ ba. Tập hợp các bộ ba RDF tạo ra một đồ thị, gọi là đồ thị RDF. Ngôn ngữ truy vấn SPARQL lấy thông tin từ các đồ thị RDF, nó cung cấp các tính năng sau:
- Chiết xuất thông tin dưới dạng các URI, các node trắng (blank node), các plain literal và typed literal.
- Chiết xuất các đồ thị con RDF.
- Xây dựng các đồ thị RDF mới dựa trên thông tin của các đồ thị truy vấn.
2.2.3. RDF DATASET
Mô hình dữ liệu RDF thể hiện thông tin về các đồ thị bao gồm các bộ ba với các subject, predicate và object. Các kho dữ liệu RDF chứa nhiều các đồ thị RDF và thông tin bản ghi về mỗi đồ thị và nó cho phép một ứng dụng để thực hiện các truy vấn có liên quan đến thông tin từ nhiều hơn một đồ thị.
Định nghĩa 2.1: Một RDF Datasset đại diện cho một tập hợp các đồ thị. RDF Dataset bao gồm một đồ thị mặc định (defaut graph) và hoặc không có hoặc có nhiều đồ thị được đặt tên (named graph). Trong đó các đồ thị được đặt tên được định danh bởi một URI.
Đồ thị được sử dụng cho việc đối sánh một mẫu đồ thị cơ sở là đồ thị đang hoạt động (active graph). Ở trong các phần trước tất cả các truy vấn đều được thực thi đối với một đơn đồ thị, điều đó có nghĩa là đồ thị mặc định của RDF Dataset chính là đồ thị đang hoạt động. Từ khóa GRAPH dùng để chỉ định đồ thị đang hoạt động là một trong các đồ thị được đặt tên của Dataset nằm trong truy vấn.
Định nghĩa của RDF Dataset không hạn chế mối quan hệ của đồ thị được đặt tên và đồ thị mặc định. Thông tin có thể được lặp đi lặp lại trong các đồ thị khác nhau. Có hai chú ý ta cần xem xét:
– Để có thông tin trong đồ thị mặc định phải bao gồm các thông tin gốc trên các đồ thị được đặt tên.
– Nên bao gồm các thông tin trên đồ thị đặt tên trong đồ thị mặc định.
Hệt như SQL cho phép người sử dụng truy xuất và sửa đổi dữ liệu trong cơ sở dữ liệu quan hệ, SPARQL cung cấp chức năng y hệt cho các cơ sở dữ liệu đồ họa NoSQL như GraphDB.
Hơn nữa, một truy vấn SPARQL cũng có thể được thực thi trong bất kỳ cơ sở dữ liệu nào mà có thể được xem như RDF thông qua phần mềm trung gian (middleware). Ví dụ, cơ sở dữ liệu quan hệ có thể được yêu cầu truy vấn với SPARQL bằng việc sử dụng phần mềm ánh xạ cơ sở dữ liệu quan hệ sang RDF – RDB2RDF (Relational Database to RDF).
Đây là những gì làm cho SPARQL trở thành ngôn ngữ mạnh mạnh để tính toán, lọc, tổng hợp và có chức năng truy vấn tiếp (subquery).
Tương phản với SQL, các truy vấn SPARQL không bị ràng buộc phải làm việc bên trong một cơ sở dữ liệu: Các truy vấn liên đoàn (Federated queries) có thể truy cập nhiều kho dữ liệu (các điểm cuối). Hệ quả là, SPARQL vượt qua được các ràng buộc do sự tìm kiếm cục bộ đặt ra.
Sức mạnh của SPARQL cùng với sự mềm dẻo của RDF có thể dẫn tới các chi phí phát triển thấp hơn khi mà việc pha trộn các kết quả từ nhiều nguồn dữ liệu là dễ dàng hơn.
CHƯƠNG 3
PHÁT TRIỂN HỆ THỐNG TRUY VẤN DỮ LIỆU TÙY CHỌN DỰA TRÊN NGỮ NGHĨA CỦA CÂU TRUY VẤN
Trong chương này, luận văn sẽ phát triển mô hình truy vấn dữ liệu với đầu vào là câu truy vấn bằng NNTN và đầu ra là câu truy vấn dữ liệu tùy chọn trường hợp câu truy vấn Insert và Update. Đồng thời, chương này cũng trình bày xây dựng và cài đặt mô hình hệ thống đã đề xuất để thực nghiệm và đánh giá mô hình
3.1. ĐẶT VẤN ĐỀ
3.2. MÔ HÌNH CÂU TRUY VẤN NNTN SANG SQL VÀ SPARQL

Mô hình hệ thống tổng quan kế thừa những bước cơ bản của hai quy trình trong các hệ thống đã được xây dựng trước đó:
– Quy trình chuyển đổi câu truy vấn bằng NNTN có cấu trúc sang câu truy vấn SQL: phân tích câu, xác định loại câu truy vấn, các thành phần của câu truy vấn đó, từ đó tạo thành câu truy vấn SQL.
– Quy trình từ câu truy vấn SQL sang câu truy vấn SPARQL: phân tích câu truy vấn SQL, ánh xạ sang câu truy vấn SPARQL.
Đồng thời tích hợp hai quy trình vào một mô hình để giải quyết mục đích là truy vấn dữ liệu tùy chọn dựa trên ngữ nghĩa của câu truy vấn.
Cấu trúc câu truy vấn bằng NNTN và kỹ thuật xử lý
Chuyển đổi sang câu truy vấn Insert
Dựa vào tìm hiểu về cấu trúc, thành phần của câu truy vấn INSERT ở chương I, có thể thấy thành phần chính của câu gồm:
Insert into: phía sau từ khóa Insert into là chỉ định tên của bảng muốn thêm hàng.
Values: sau từ khóa From là danh sách các giá trị trong hàng cần thêm.
Select expression: Trả về các dòng giá trị cần thêm vào trong bảng đích.
Bảng 3.2. Danh sách từ và giá trị tương trong thành phần câu INSERT
| Từ khóa | Từ khóa tương ứng trong SQL |
| “insert”, “add”, “append”, “enter”, “insertion”, “get into”, “sell into”, “entered into”, “join in”, “join into” | Insert into |
| “values”, “include”, “worth”, “scope”,”fair value”, “import” | Values |
| “put”, “initialize”,”fill”, “introduce”, “selective”, “select show” | Select expression |
Bước 1: Xác định thành phần của câu truy vấn Insert bằng NNTN có cấu trúc tương ứng với cấu trúc câu truy vấn SQL
Bước 2: Sau khi xác định được các thành phần của câu truy vấn, sử dụng kỹ thuật ánh xạ các thuộc tính, bảng có tên gọi bằng NNTN với bộ từ điển được xây dựng để xác định tên được quy định trong CSDL. Cuối cùng tiến hành tổng hợp các thành phần xác định được của câu truy vấn để tạo thành câu truy vấn SQL hoàn chỉnh.
3.2.3. Chuyển đổi sang câu truy vấn UPDATE
Bước 1: Xác định thành phần của câu truy vấn Update bằng NNTN có cấu trúc tương ứng với cấu trúc câu truy vấn SQL
Bước 2: Xác định thành phần của câu truy vấn bằng NNTN có cấu trúc tương ứng với cấu trúc câu truy vấn SQL
- Câu truy vấn UPDATE
Dựa vào tìm hiểu về cấu trúc, thành phần của câu truy vấn SELECT ở chương I, có thể thấy thành phần chính của câu gồm:
Update: phía sau từ khóa Update là xác định tên của bảng muốn cập nhật.
Set: sau từ khóa Set là một hoặc nhiều mệnh đề được gán giá trị mới cho các cột trong bảng.
Where: sau từ khóa Where là biểu thức tìm kiếm dùng để lọc các hàng dữ liệu trả về.
Để xác đinh các thành phần của câu UPDATE, mô hình cũng sử dụng kỹ thuật ánh xạ các từ vào bộ từ điển để tìm ra vị trí của từng thành phần của câu UPDATE trong truy vấn bằng NNTN. Bộ từ điển được xây dựng như Bảng 3.2
Bảng 0.1. Danh sách từ và giá trị tương trong thành phần câu SELECT
| Từ khóa | Từ khóa tương ứng trong SQL |
| “update”, “amend”, “modernize”, “refresh”, “refurbish”, “rejuvenate”, “renew”, “renovate”, “restore”, “revise” | Update |
| “set”, “values”, “funtion”, “column reference” | Set |
| “filter”, “for”, “during”, “with”, “where” | Where |
GIỚI THIỆU VỀ FRAMEWORK APACHE OPENNLP VÀ GENERAL SQL PARSER
OpenNLP được bắt đầu phát triển vào năm 2000 bởi Jason Baldridge và Gann Bierner. Các thư viện Apache OpenNLP là một thư viện Java phục vụ cho việc xử lý văn bản NNTN. Nó bao gồm nhiều thành phần hỗ trợ các nhiệm vụ NLP phổ biến nhất, ví dụ như bộ tách từ, phân chia câu, gán nhãn từ loại, trích xuất thực thể có tên, phân tích cú pháp, phân giải đồng tham chiếu. Những nhiệm vụ này rất cần thiết để xây dựng các dịch vụ xử lý văn bản nâng cao hơn. OpenNLP cũng bao gồm các dữ liệu ngẫu nhiên cực đại và thuật toán Perceptron dựa trên học máy
CÀI ĐẶT MÔ HÌNH ĐÃ ĐỀ XUẤT
Dựa vào mô hình hệ thống tổng quan và phần giới thiệu các framework hỗ trợ nhiệm vụ chuyên biệt trong hệ thống, luận văn xây dựng nên một sơ đồ cài đặt giải pháp chi tiết như Hình 3.7.

KẾT QUẢ CHƯƠNG TRÌNH
Cơ sở dữ liệu dùng cho thực nghiệm
Cơ sở dữ liệu được xây dựng đơn giản để kiểm tra việc chuyển đổi câu truy vấn tự nhiên có cấu trúc sang câu truy vấn SQL và SPARQL. Mục đích cơ sở dữ liệu là lưu trữ thông tin của một liên hệ (contact) chứa các thông tin gồm họ tên, địa chỉ và số điện thoại nhà, địa chỉ và số điện thoại nơi làm việc, địa chỉ mail.
- Cơ sở dữ liệu quan hệ
CSDL quan hệ được xây dựng với tên bảng là đối tượng liên hệ (contact), với các thuộc tính có khóa chính là id, bảng contact được biểu diễn như sau:
contact (id, name, prename, homeaddress, hometelephone, workaddress, worktelephone, email)
- Cơ sở dữ liệu ngữ nghĩa
CSDL ngữ nghĩa được xây dựng tương tự như của CSDL quan hệ gồm class contact, với các thuộc tính dữ liệu (data properties) tương tự thuộc tính được biểu diễn ở CSDL quan hệ.
Hệ thống thực nghiệm NL2SQL-SPARQL
- Tác nhân: Người dùng.
- Ca sử dụng
– Truy vấn CSDL bằng NNTN có cấu trúc: khi người dùng muốn truy vấn dữ liệu, người dùng nhập câu truy vấn bằng NNTN và chọn mô hình CSDL.
– Truy vấn dữ liệu mySQL: khi người dùng muốn truy vấn CSDL mySQL.
– Truy vấn dữ liệu RDF: khi người dùng muốn truy vấn CSDL RDF.
– Cấu hình CSDL mySQL: muốn kết nối tới CSDL mySQL, người dùng cần cấu hình các thông số như: hostname, username, password, database name
– Cấu hình CSDL RDF: cấu hình đường dẫn tới tập tin lưu trữ CSDL RDF.
– Tạo câu truy vấn SQL: ca sử dụng thực hiện phân tích câu truy vấn NNTN có cấu trúc để sinh câu truy vấn SQL.
– Tạo câu truy vấn SPARQL: ca sử dụng thực hiện phân tích câu truy vấn SQL để sinh câu truy vấn SPARQL.
– Kết nối CSDL mySQL: thực hiện kết nối tới CSDL mySQL dựa trên các thông tin đã được cấu hình.
– Kết nối CSDL RDF: thực hiện kết nối tới CSDL RDF dựa trên đường dẫn đã được cấu hình.

Hình 3.8. Sơ đồ ca sử dụng của chương trình
Trước khi chương trình được thực thi cần một vài tham số để thiết lập kết nối tới CSDL mySQL và CSDL RDF.
Thiết lập các thông tin dùng để kết nối mySQL: hostname, cổng kết nối, tên CSDL, username, password để kết nối cơ sở dữ liệu.
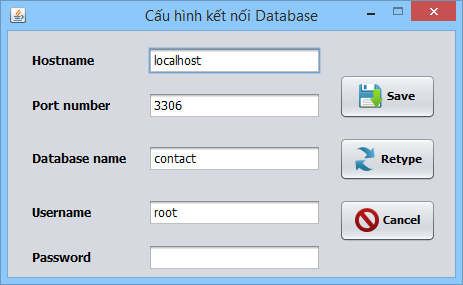
Hình 3.9. Giao diện cấu hình cơ sở dữ liệu mySQL
– Thiết lập đường dẫn tới file dữ liệu RDF.
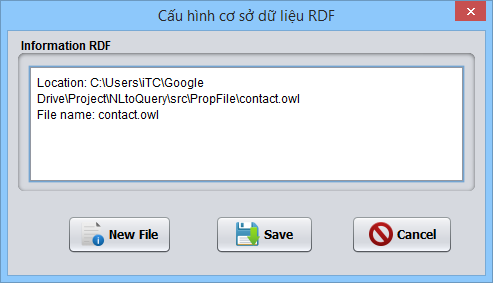
Hình 3.10. Giao diện cấu hình cơ sở dữ liệu RDF
Giao diện chính của NL2SQL-SPARQL như trong Hình 3.11 chứa:
– Một nhóm nút cho phép chọn kết quả sinh ra của câu truy vấn NNTN là SQL hoặc SPARQL, khi chọn một trong hai nút sẽ hiện ra thông tin cấu hình CSDL tương ứng;
– Giao diện nhập câu truy vấn bằng NNTN, có chứa một số mẫu câu truy vấn có sẵn. Bên cạnh có một danh sách chứa các từ khóa gợi ý cho người dùng để nhập câu truy vấn bằng NNTN;
– Giao diện chứa câu kết quả câu truy vấn được sinh ra;
– Bảng chứa kết quả truy vấn CSDL;
– Các nút thực thi.
add “contact” with “Last Name” = “Thảo”, “First Name” is “Nguyễn Phương”, “Email” = nguyenphuongthao2012@gmail.com
INSERT INTO contact (name, prename, email) VALUES (‘Thảo’, ‘Nguyễn Phương’, ‘nguyenphuongthao2012@gmail.com’)
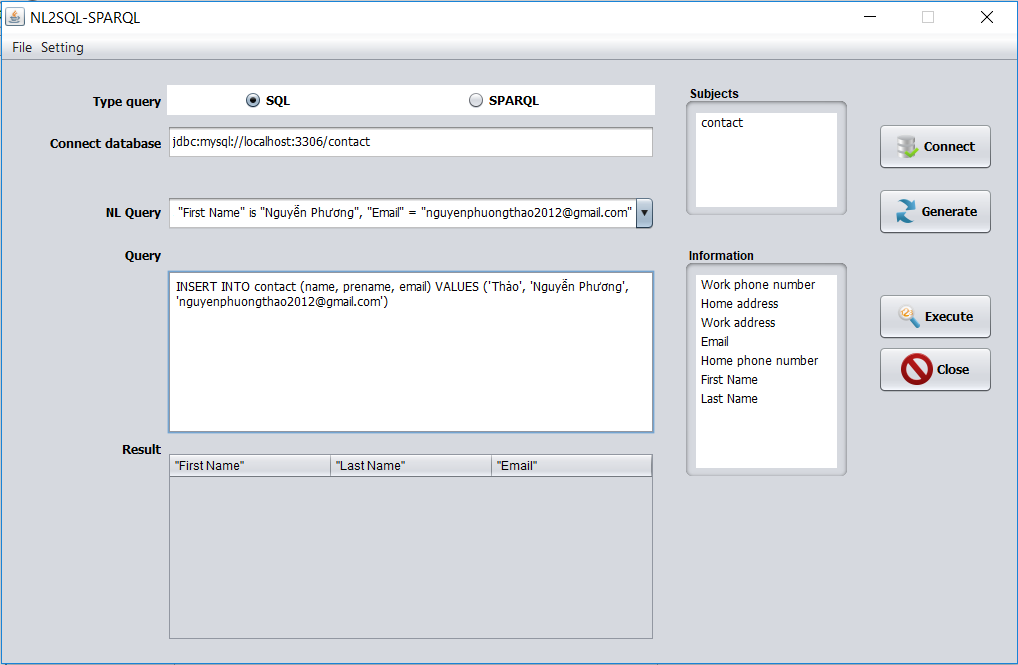
Hình 3.11. Giao diện chuyển đổi sang SQL
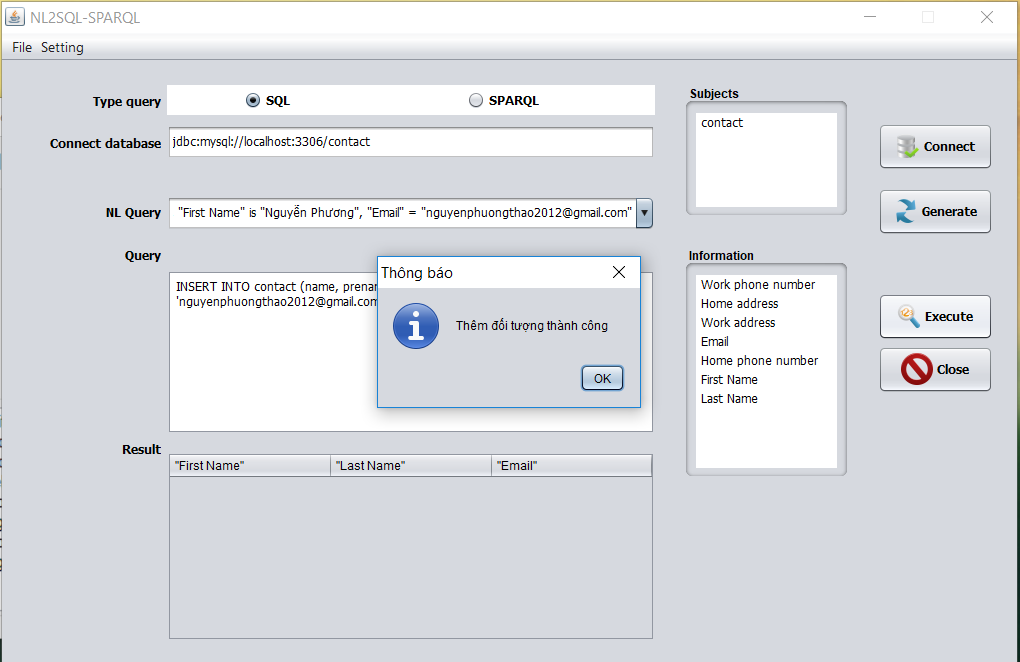
Hình 3.12. Giao diện chuyển đổi sang SQL
PREFIX contact: <http://www.semanticweb.org/itc/ontologies/ 2016/3/contact#>
INSERT DATA {
contact:contact9 contact:name ‘Thảo’;
contact:prename ‘Nguyễn Phương’;
contact:email ‘nguyenphuongthao2012@gmail.com’.
}
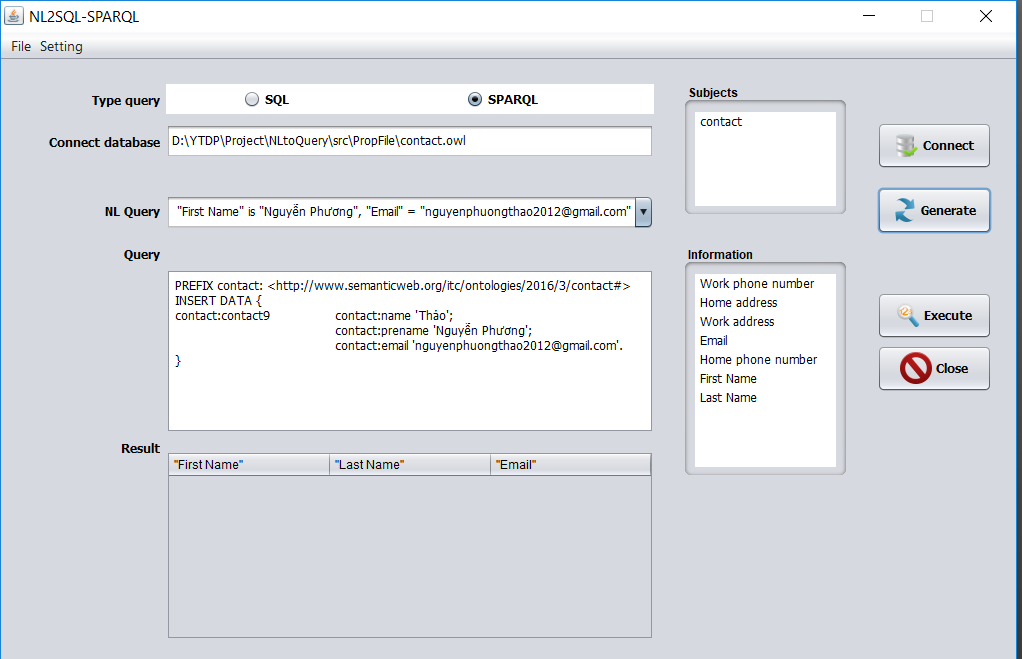
Hình 0.12. Giao diện chuyển đổi sang SPARQL
update “contact” for “Email” is “nguyenphuongthao2012 @gmail.com” set “Last Name” is “Hoa”
UPDATE contact SET name = ‘Hoa’ WHERE email = ‘nguyenphuongthao2012@gmail.com’
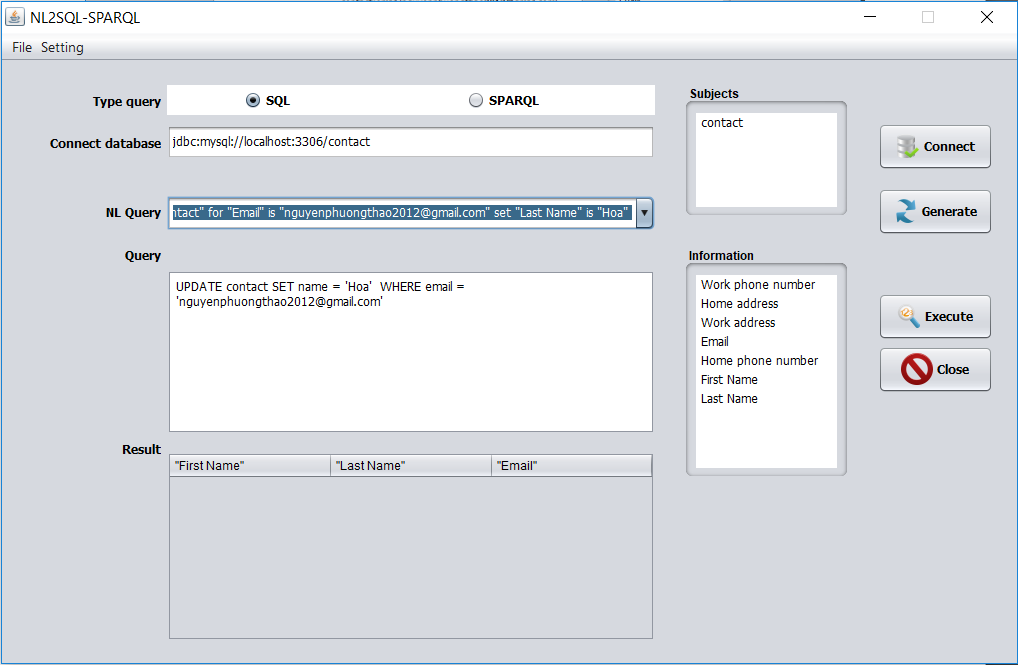
Hình 3.13. Giao diện chuyển đổi sang SQL với câu lệnh Update
PREFIX contact: <http://www.semanticweb.org/itc/ontologies/ 2016/3/contact#>
DELETE
?x contact:name ?name
INSERT
?x contact:name ‘Hoa’
WHERE{
?x contact:email ‘nguyenphuongthao2012@gmail.com’}
Hình 3.14. Giao diện chuyển đổi sang SPARQL
Kiểm tra lại trong dữ liệu
Hình 3.11. Giao diện kiểm tra lại dữ liệu
3.6. KẾT CHƯƠNG
Chương này luận văn đã trình bày về bài toán yêu cầu đặt ra trong việc thực hiện truy vấn INSERT, UPDATE dựa trên ngữ nghĩa của câu truy vấn, và đã đề xuất mô hình tổng quan để giải quyết bài toán đặt ra. Từ câu truy vấn ngôn ngữ tự nhiên có cấu trúc, phân tích tạo ra câu truy vấn SQL, từ câu truy vấn SQL chuyển đổi sang câu truy vấn SPARQL. Đồng thời luận văn đã trình bày về framework Apache OpenNLP và framework General SQL Parser, và áp dụng các framework này vào quá trình xử lý trong hệ thống như đã mô tả ở Hình 3.7. Và liệt kê các hàm xử lý chính được cài đặt trong chương trình.
KẾT LUẬN
Mục tiêu chính của đề tài là phát triển và hoàn thiện mô hình NL2SQL – PARQL để có thể thực thi các truy vấn INSERT, UPDATE khi truy vấn bằng ngôn ngữ tự nhiên.
Để thực hiện mục tiêu đã đề ra, tôi đã tiến hành tìm hiểu hệ thống chuyển đổi câu truy vấn bằng ngôn ngữ tự nhiên sang câu truy vấn SQL và chuyển đổi câu truy vấn SQL sang câu truy vấn SPARQL để tìm các bước thực hiện chung của các hệ thống đó. Từ các bước thực hiện chung đó, phát triển mô hình hệ thống truy vấn dữ liệu tùy chọn dựa trên ngữ nghĩa của câu truy vấn để có thể thực thi các truy vấn INSERT, UPDATE.
Luận văn đã tiến hành xây dựng hệ thống và cài đặt bằng ngôn ngữ Java, đồng thời sử dụng bộ công cụ Apache OpenNLP để hỗ trợ trong việc thực hiện các bước phân tích NNTN. Sau đó, sử dụng kỹ thuật từ điển để tìm ra các từ tương ứng để xây dựng câu truy vấn SQL cho CSDL quan hệ. Trong trường hợp người dùng muốn chuyển đổi câu truy vấn NNTN thành câu truy vấn SPARQL cho CSDL ngữ nghĩa, mô hình sử dụng bộ tích hợp General SQL Parser để hỗ trợ trong việc phân tích câu truy vấn SQL, sau đó xây dựng câu truy vấn cho CSDL ngữ nghĩa. Mô hình này đã được thực nghiệm bằng hệ thống NL2SQL-SPARQL. NL2SQL-SPARQL đã thử nghiệm thành công việc sinh câu truy vấn INSERT, UPDATE sang mô hình CSDL quan hệ và sang CSDL ngữ nghĩa.
2. Hướng phát triển của đề tài
Hệ thống NL2SQL-SPARQL sử dụng kỹ thuật từ điển, cho nên hiệu quả của hệ thống phụ thuộc rất nhiều vào từ vựng trong bộ từ điển, đây là khó khăn lớn nhất và là vấn đề cơ bản của bất kỳ hệ thống xử lý ngôn ngữ tự nhiên nào. Việc mở rộng từ điển và phân tích sâu hơn ngữ nghĩa của câu truy vấn bằng NNTN sẽ là một trong những hướng nghiên cứu tiếp theo của luận văn.
Hệ thống vẫn chỉ thực hiện chuyển đổi câu truy vấn ngôn ngữ tự nhiên sang câu truy vấn SQL ở dạng đơn giản và chỉ trên câu lệnh INSERT, UPDATE. Vì vậy, hướng sắp tới tôi sẽ khắc phục những hạn chế về khả năng chuyển đổi câu truy vấn từ ngôn ngữ tự nhiên sang câu truy vấn SQL. Mở rộng bộ từ điển và áp dụng NL2SQL-SPARQL cho các loại câu truy vấn còn lại. Cuối cùng, việc mở rộng mô hình để hỗ trợ thêm nhiều loại mô hình CSDL khác ngoài CSDL quan hệ và CSDL ngữ nghĩa, đồng thời hỗ trợ câu truy vấn NNTN bằng tiếng Việt cũng là một trong những hướng phát triển phát triển khác của luận văn.
Trong tương lai, tôi sẽ cố gắng cải thiện các hạn chế, mở rộng các chức năng để có thể áp dụng hệ thống vào thực tế, nhằm phục vụ cho sự phát triển của hệ thống chuyển đổi câu truy vấn bằng ngôn ngữ tự nhiên có cấu trúc sang dạng câu truy vấn thích hợp với các hệ thống cơ sở dữ liệu.
E:\DỮ LIỆU COP CỦA CHỊ YẾN\DAI HOC DA NANG\HE THONG THONG TIN\NGUYEN THI PHUONG THAO\New folder\TOM TAT



